I’ve twisted my brain into a pretzel thinking about this, so I hope this makes sense.
The goal
My team manages a classroom training course for a group of employees who are within their first 30 days with the company. For each reporting period, I need to identify 3 things:
The numer of employees eligible to take the training (eligibility is based on job type, location, and tenure in days [within 30 days from hire date])
The number of eligible employees who took the training
The % of eligible employees who took the training
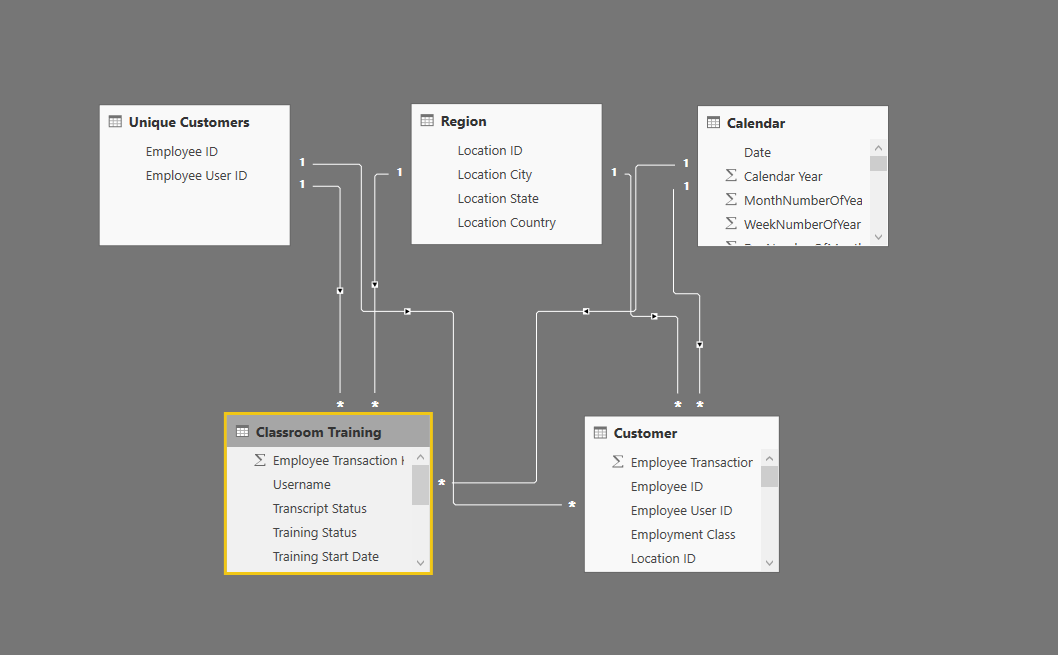
I have 5 tables in my data model with active and inactive relationships. I’ve include a picture of the data model below.
ClassroomTraining - fact table w/ training attendance info (active relationship with each lookup table)
Customer- lookup table with employee records (inactive relationships with the other data tables for eligible customer calculations)
Region - lookup table with locations grouped into regions
Calendar - lookup table with a standard calendar format
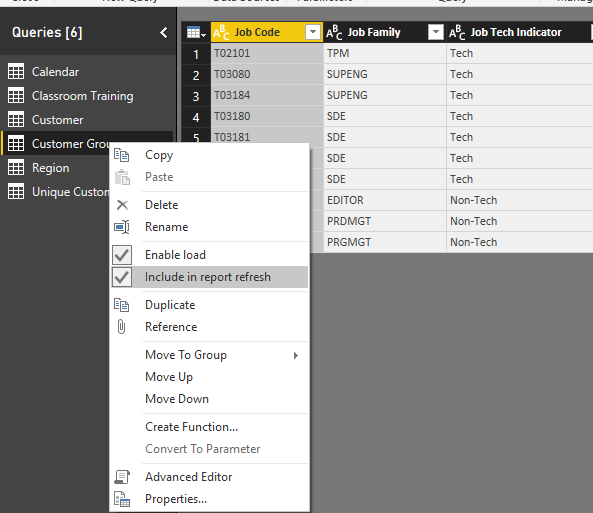
CustomerGroup - lookup table with job details like level, job title, and category
The problems
(I’m including both in 1 post because I think the key to solving both is the same. Happy to split them up if that would be best.)
I can write measures that identify eligible employees based on job type and location, but can’t seem to factor in the 30-day window from their Last Hire Date.
Because an eligible employee’s 30-day window can include 2 report months, I need to exclude employees who took the training in the previous report month from the count of eligible employees in the next report month. For example, if an eligible employee was hired on April 25, 2018, and they took the training on April 30, I need to exclude them from the total # of eligible employees for May even though their 30-day new hire window extends into May.
Ok, there’s a bit to this. And maybe a bit too much going on to understand everything.
I’m trying to initially think top level simplification here.
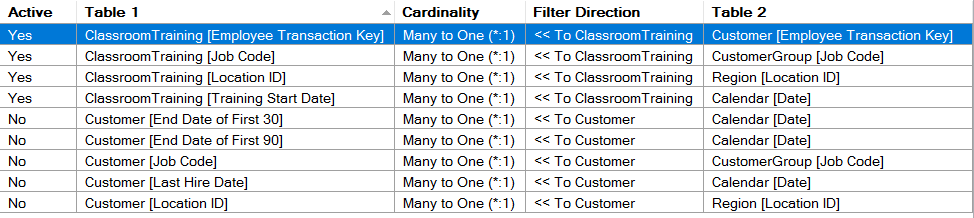
I don’t like the way those inactive relationship are to be honest. I don’t even think you need them for what asking for.
All those inactive relationships are a recipe for mass confusion.
I’ve been thinking about it for a bit.
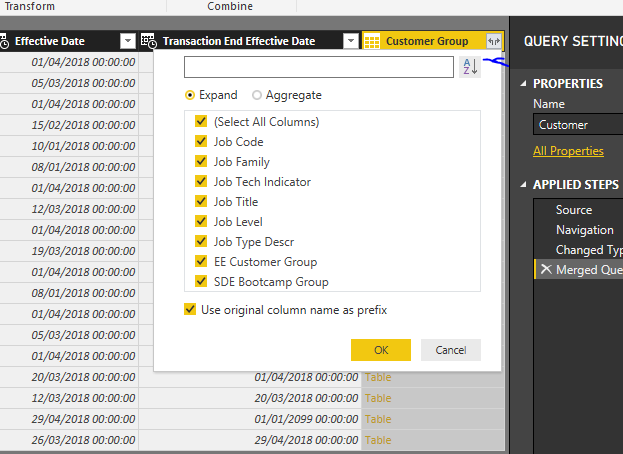
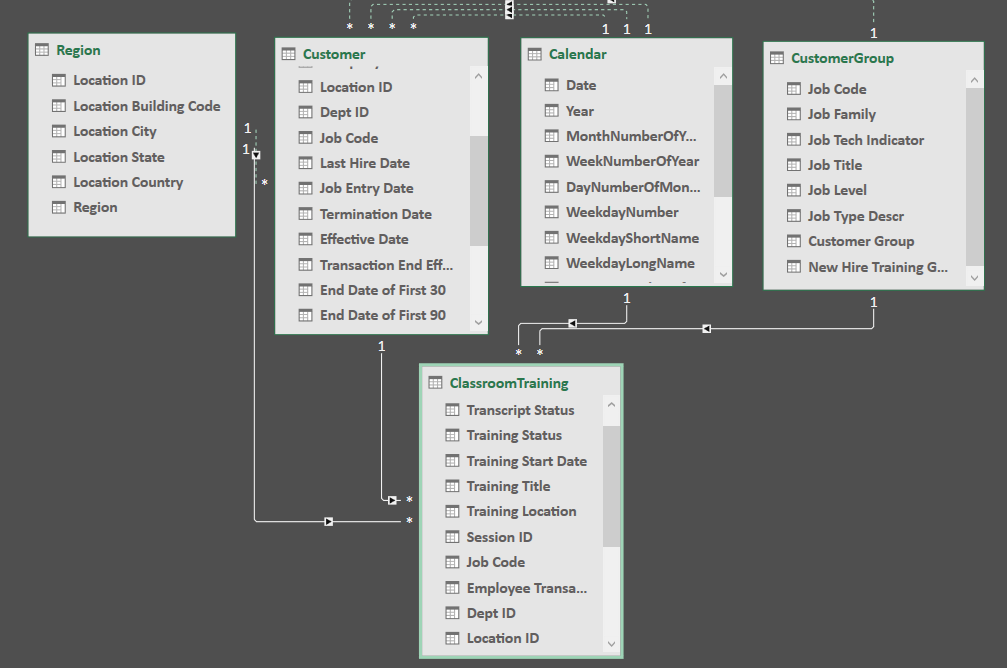
My advice it to have a big master Customer Lookup Table. You should have the existing, then merge the customer group table into that one by the looks of it using the ‘Job Code’ columns. This will give you a full Customer table.
Get rid of all the date relationships between the customer table and the date table.
Then all you need to do for the 30 day window logic is build this inside a calculated column inside the update customer table. Just using IF( something something). This will then just be a filter you can use that has customer in or out of the 30 day window.
I think the same technique can be applied to question 2 as well. It’s just creating the right calculated column logic. Once that is done you’ll have your filter.
Let’s do this clean up first and then see what left after that.
I just get the feeling here you may be over thinking it a little bit, and a bit of that is to do with all the funky relationships which on the face of it to me aren’t required.
Thank you for taking a look at my post. First, my apologies. I used the wrong the terminology in first post. The 4 tables I listed above as data tables are actually dim/lookup tables: Customer, Region, Calendar, and CustomerGroup. I will fix this in the original post.
I fear I’m so new to all this that I know just enough to cause trouble.
Re: all the inactive relationships - I see your point and will remove them.
Re: combining the Customer and CustomerGroup tables - The Customer table currently has about 227,000 rows with a few thousand added every month. It contains a row for every version of the customer/employee in the table.
With so many rows, would adding 7 columns from the CustomerGroup table to the Customer table cause performance issues either with refreshing the query or a calculated column?
Re: the IF clause - The [End Date of First 30] column of the Customer lookup table contains the last date in the employees 30-day new hire window. I’m thinking this is the date I would need for the IF clause to compare to the date in the [Training Start Date] column of the ClassroomTraining fact table to calculate metric #2 from the list above (the # of eligible employees who took the training). Am I on the right track?
Ok yes definitely delete those relationships first.
When you say every version…can a customer be reference multiple times? If so, then you need to clean this up as well and have a table where the customer is only reference once.
227,000 is a lot. I’m surprise you have that many customers. That’s a lot.
Yes on your final point that does sound about right, but still to me it looks like some optimizations can be done.
I’m interested about this 227K customer table, seems way to big to me.
Yes, a single customer is referenced multiple times. I’m not sure how to go about cleaning up this table in a way that still gets me what I need. Would be super grateful for any suggestions you have.
Here’s my use case:
I work for a team that builds training for a subset of employees at our company. These employees are our customers and it’s their employee info in my Customer table.
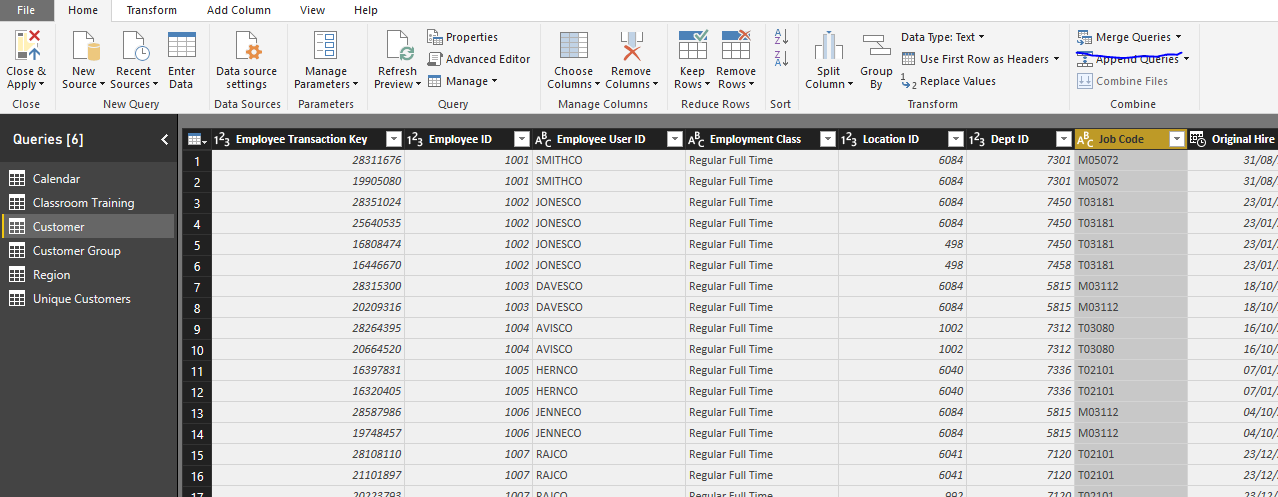
I counted the distinct customers and it’s about 94,000. My dilemma is that I need to know the department, location, and job title of each one of those employees at any point in time from 1/1/2017 to now. The primary key for this table is called the Employee Transaction Key and it is unique for each version of the employee.
In the Customer table a single customer (aka employee) can have multiple rows where their department, location, and job title are the same, but the Employee Transaction Key is different because there are other attributes about the employee that changed. Although my team doesn’t look at those other attributes, I need the unique Employee Transaction Key to reference the version of an employee on the day they took a training.
The raw data I get that tells me which employees are taking our training doesn’t include the Employee Transaction Key (Classroom Training table mentioned in the original post), so I use the Query Editor to add it to the Classroom Training table.
Would it help if I sent you a sample data set so that you could examples of the duplicates? Or maybe posted a screenshot of sample data?
I think for this one, if you could send me an example of the data you are using. Then I could atleast mock up the strategy I would employ in the model.
There’s a bit to this one, but once you simplify the data model here it will all flow nicely. It’s all about the model, getting that right is key.
You don’t have to send me everything, just a subset and I could have a look at that.
I sent the samples in an Excel file by email. A couple things to note:
The actual Customer table is even larger than I thought. To capture each version of an employee/customer from 1 Jan 2017 until now, it’s over 500k rows. Perhaps the Group By function in the Query Editor could help me remove the rows that I don’t need? (I didn’t send you 500K rows. The sample includes only 20 rows for the Customer table. )
My team is switching to an ISO calendar, so I included a Calendar table in the sample. And I’m off to watch your videos on time intelligence with custom calendars.
From here you then just want to clean up all the column names, and then delete all the ones you don’t need. Try to slim down the table to only the essential information.
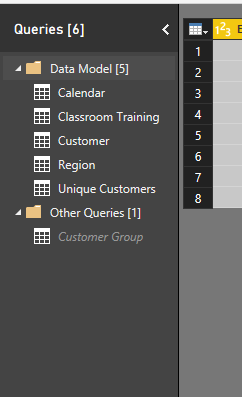
Also don’t forget to untick ‘enable load’ - this is because you’ve merged this table and don’t need to include it in the model anymore. You still need the query just not the table
All I’ve done here is really try to clean things up so the model makes sense and filters can flow naturally like a ‘waterfall’ - that’s how I like to describe them
This is how I would like to get this to look one done with all these
Thanks, Sam! I’m working through the Advanced Data Transformations & Modeling course, as you suggested. Just a few more modules to go and then I’ll try the clean up you’ve outlined above.
I completed the Advanced Data Transformations & Modeling course as you suggested and also watched the video for the events in process pattern, and I think I’m almost there.
I have the original Customer table (row for every version of an employee) as a fact table that has no relationship with the Calendar table or the Classroom Training table.
Here’s the formula I wrote to capture active employees who are within their first 30 days with the company during the report month. It’s not quite right, but I think figuring it out might be the key to solving it all.
=CALCULATE([Active Customers],
FILTER(Customers, Customers[End Date of First 30] >=MIN('Calendar'[Date]) && Customers[End Date of First 30] <=MAX('Calendar'[Date])))
Using the report month of May as an example (30 April - 27 May on our ISO calendar), I want to capture all employees with an [End Date of First 30] between 30 April and 27 June.
The formula I wrote is excluding employees with an [End Date of First 30] greater than 27 May. I think that’s because of the last statement:
&& Customers[End Date of First 30] <=MAX('Calendar'[Date])))
My guess is that I need to change the last statement to capture employees whose [End Date of First 30] <= MAX(‘Calendar’[Date]) + 30 days, but can’t figure out the syntax for the +30 days part.
Am I on the right track here? Or making a bigger mess of things?
By looking just at your formula the logic seems ok so I’m a bit confused as to where this may to tripping up.
One thing to first check is what is the MIN and MAX dates actually evaluating to. I would break these out into measures by themselves. This way you can audit what they are calculating based on the context you may have in your report page.
For the +30 days…that should be all you need. The logic would be the same as you would use in excel. What’s the problem when you use this?
Apologies for taking so long to get back on this. Your suggestion to break out the MIN and MAX dates to check what they were evaluating too was the key for me. Thank you! I was trying to get too fancy with my measures and they were more complex than I could sort out with my newbie DAX skills.
I was able to sort it all by creating measures for MIN and MAX report dates and then measures for MIN - 30 days.
MIN report date =MIN('Calendar'[Date]) MAX report date =MAX('Calendar'[Date]) MIN date minus 30 days = [MIN report date] - 30
 )
)