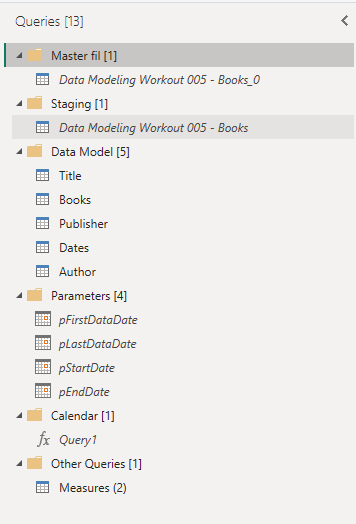
Difficulty level:
For this workout, you’re taking a break from your high-powered BI consulting job to help out a friend who runs a beloved local bookstore. They are trying to build a Power BI report to analyze information about books, authors and publishers.
However, they are running into problems getting their slicers and DAX to work properly.
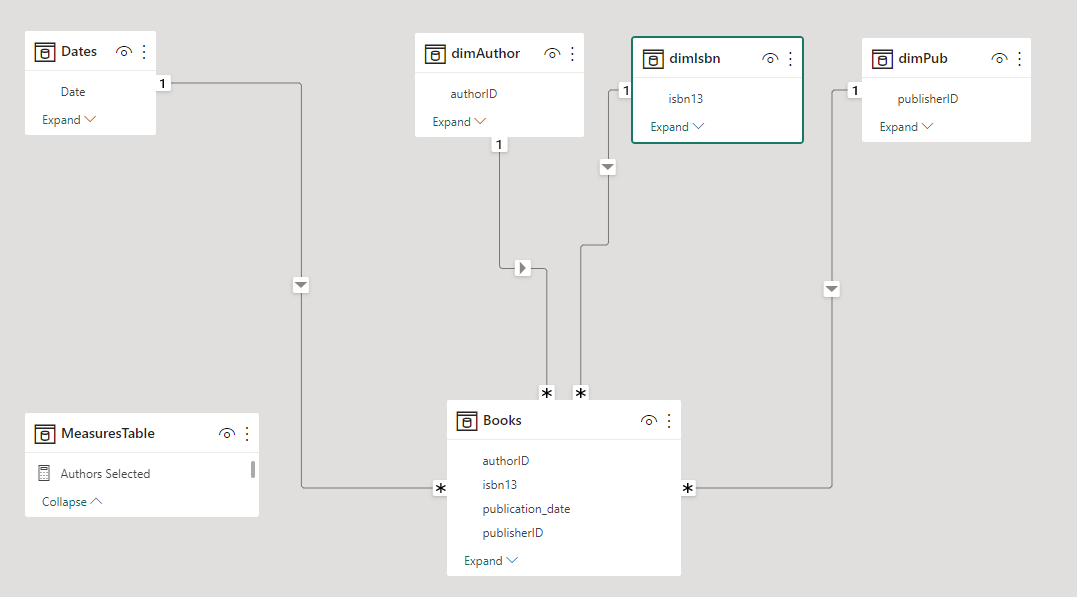
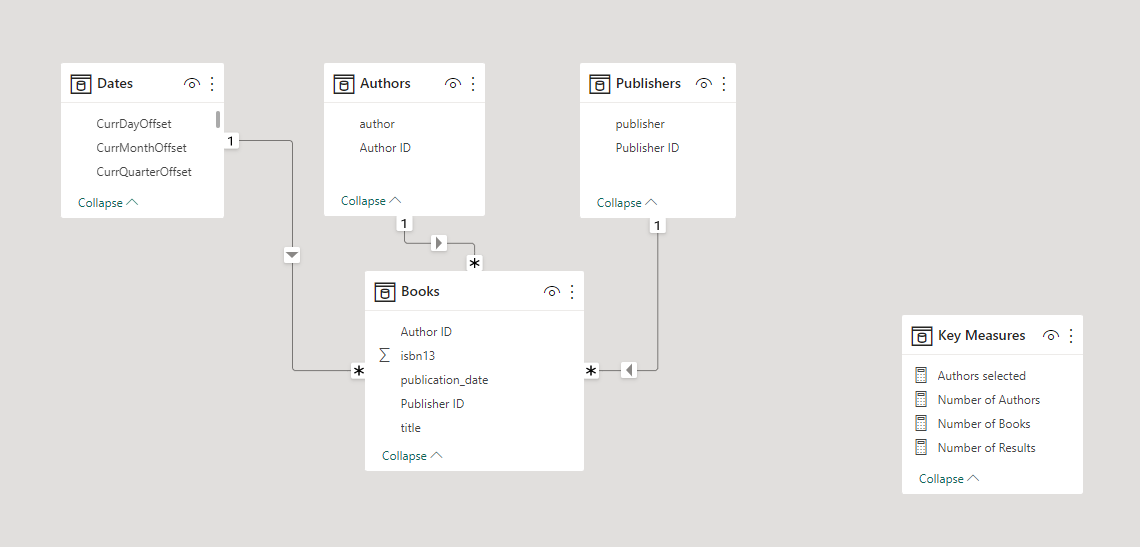
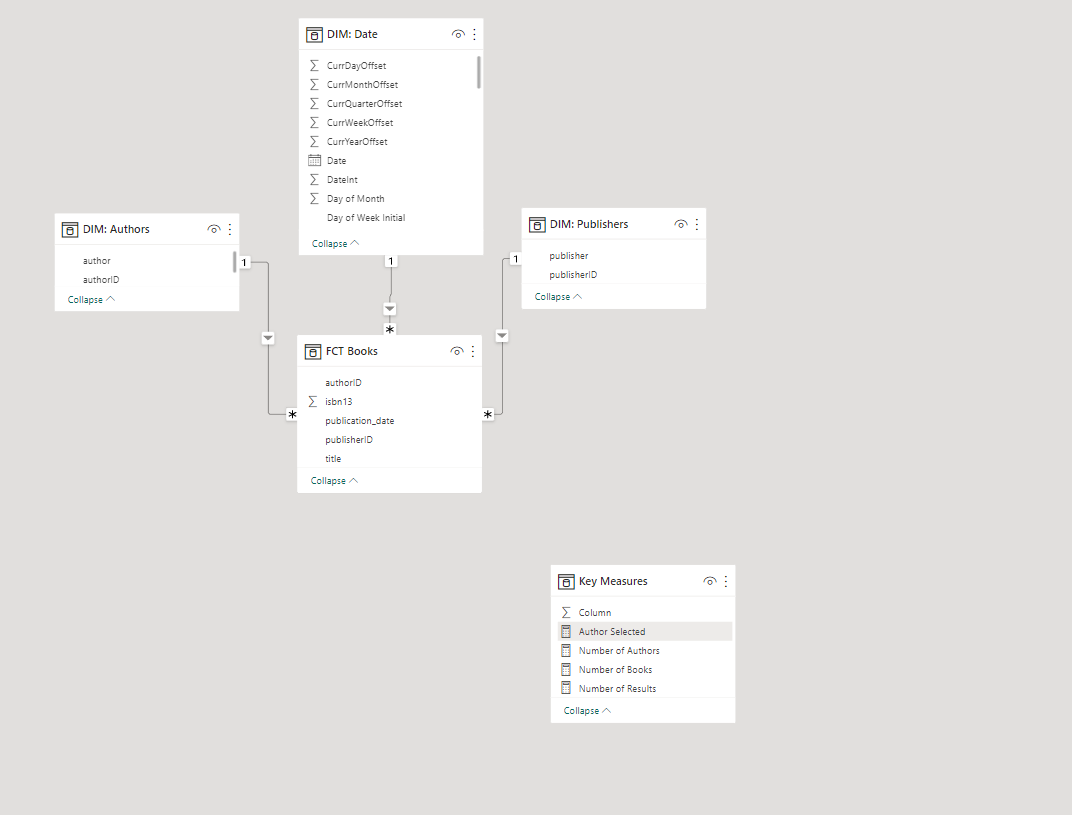
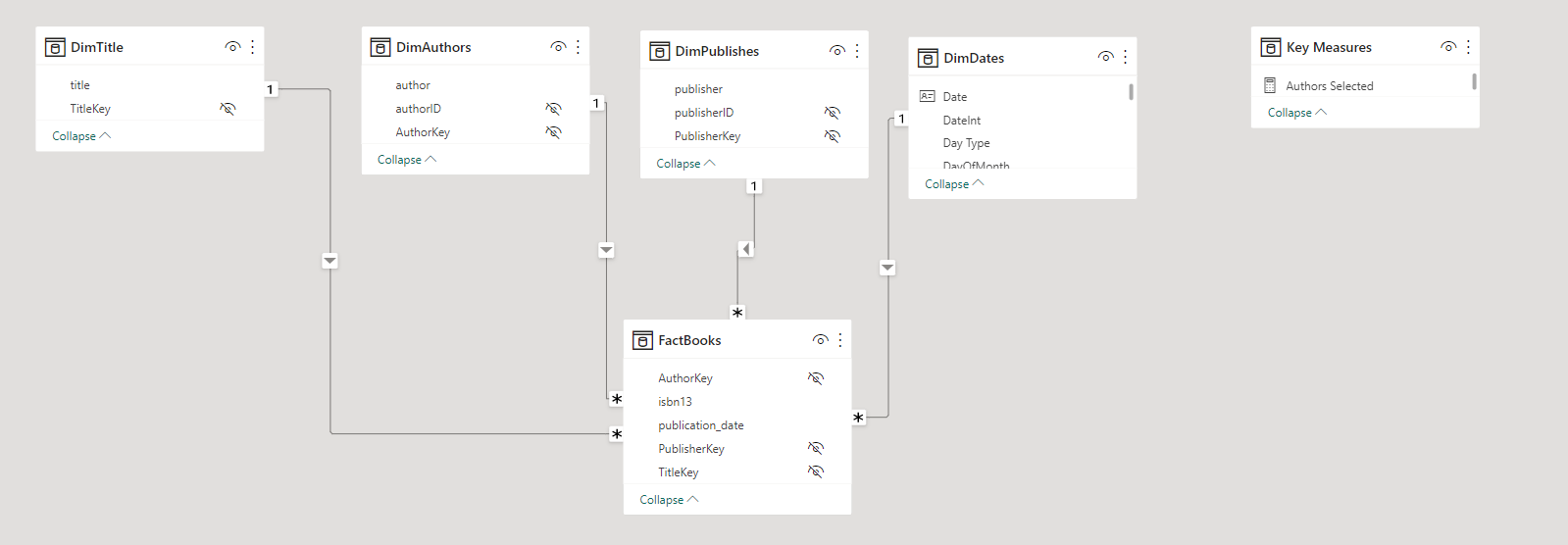
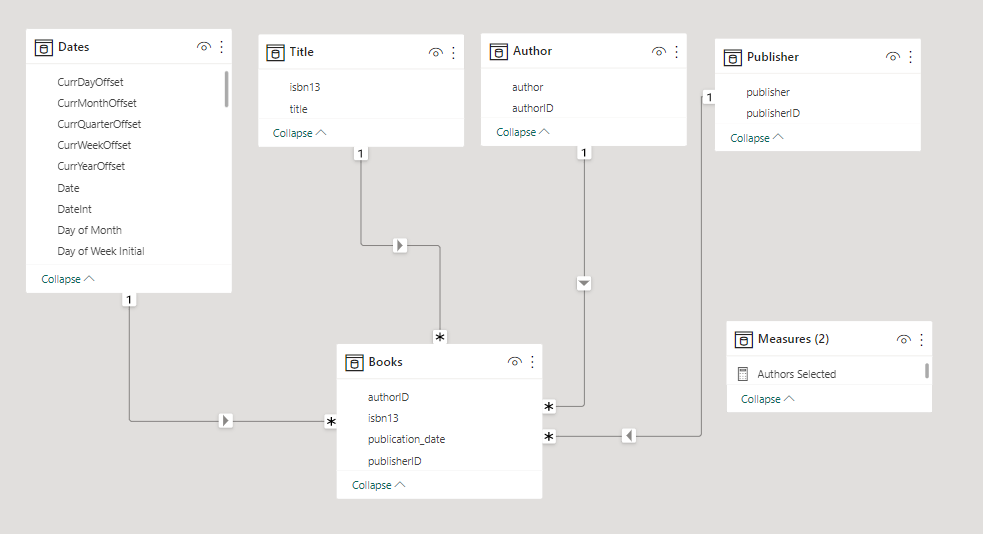
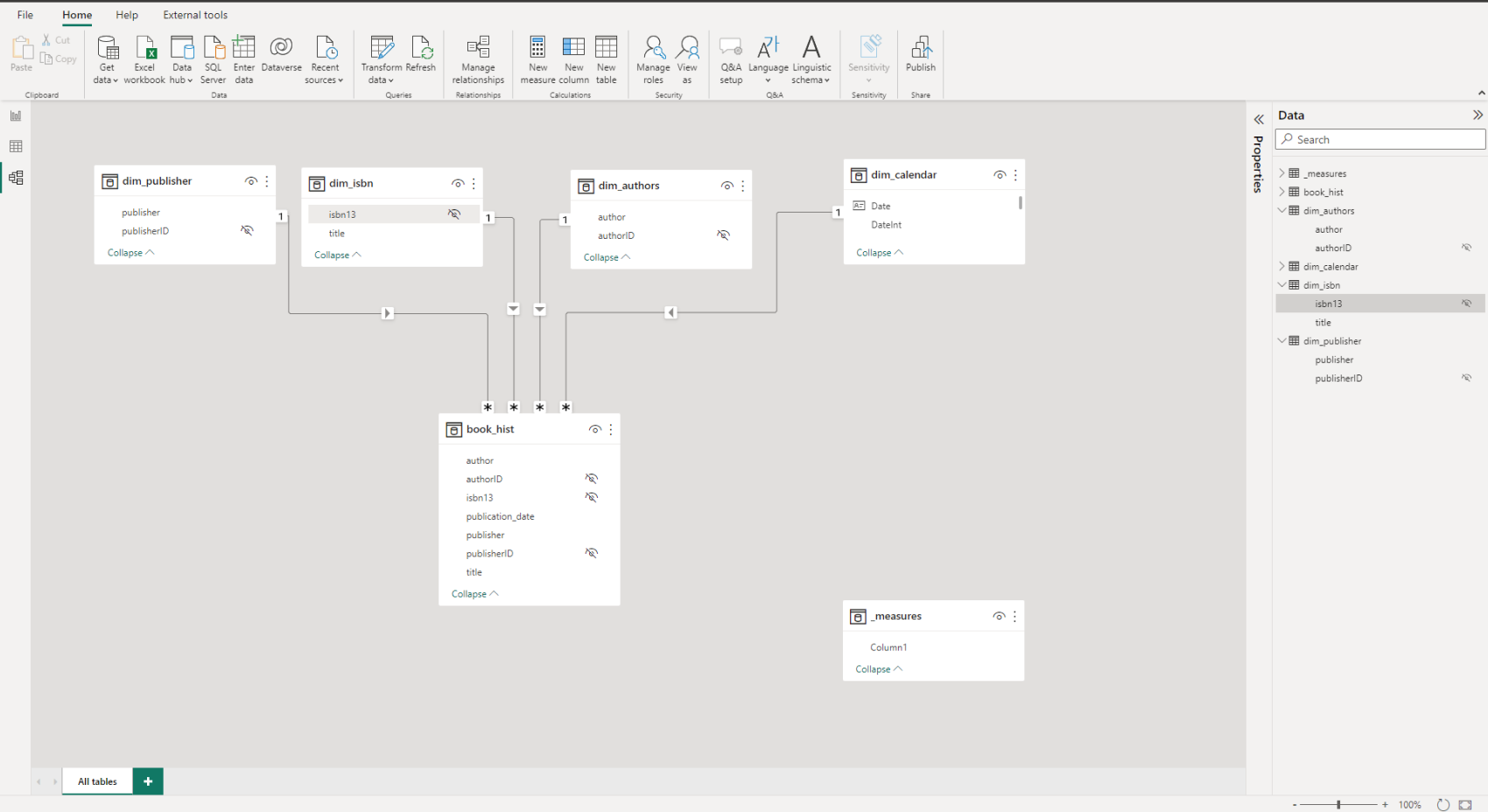
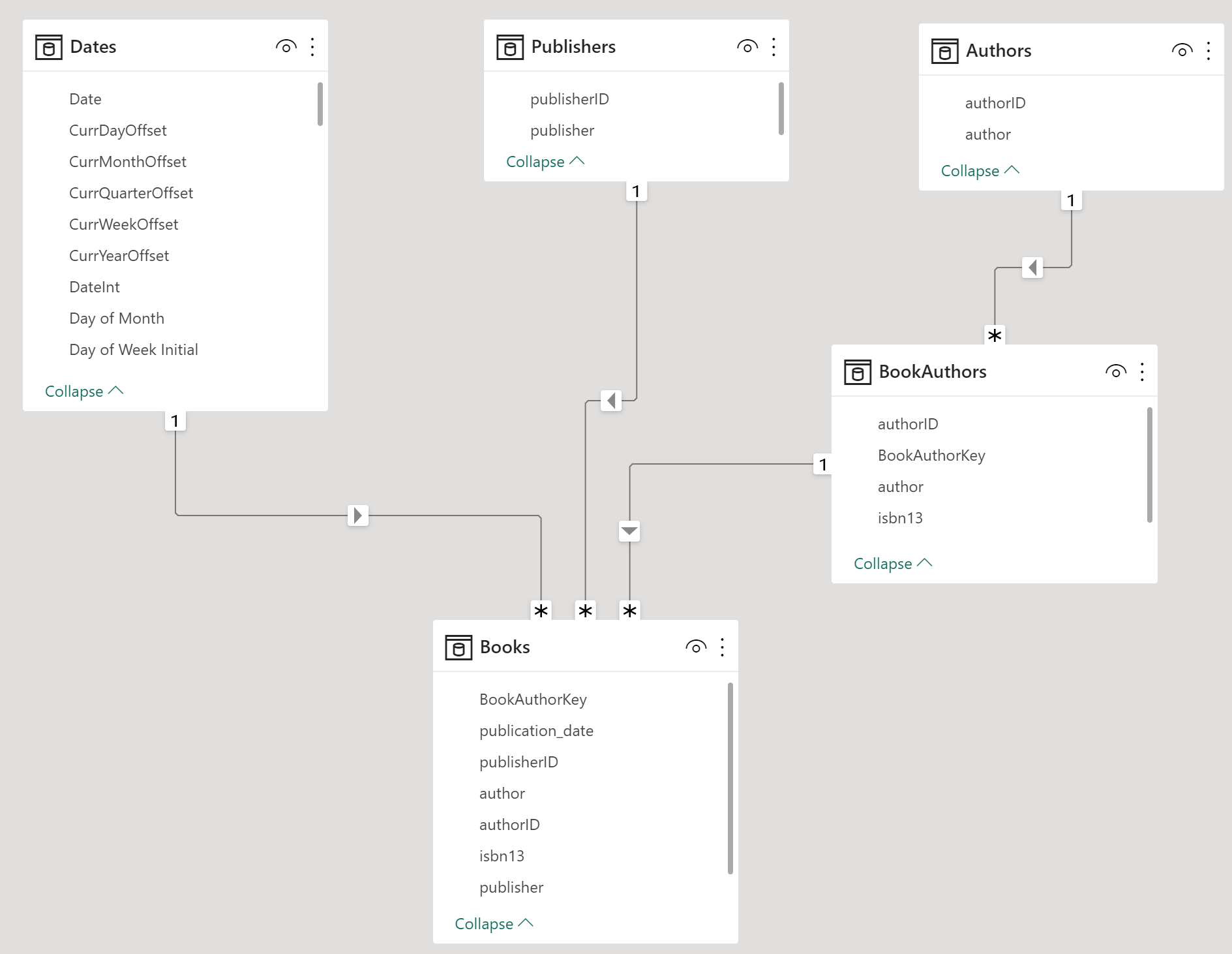
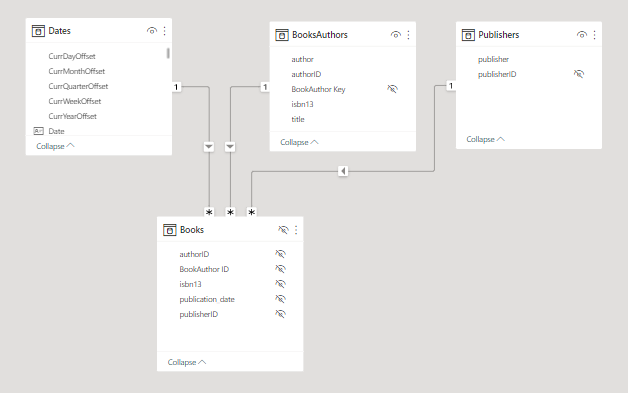
You ask how they’re handling the many-to-many relationship and just get blank stares. You explain that this scenario is a little tricker than than standard star schema model because a book can have multiple authors and a given author may have written multiple books. (For this exercise, assume that each edition of book has only one publisher though).
“Well, doesn’t that make the DAX really complicated” , they ask you?
“Nope. If you nail your data model, you can use the simplest “baby DAX” and it will work perfectly”, you answer.
‘*************************************************’
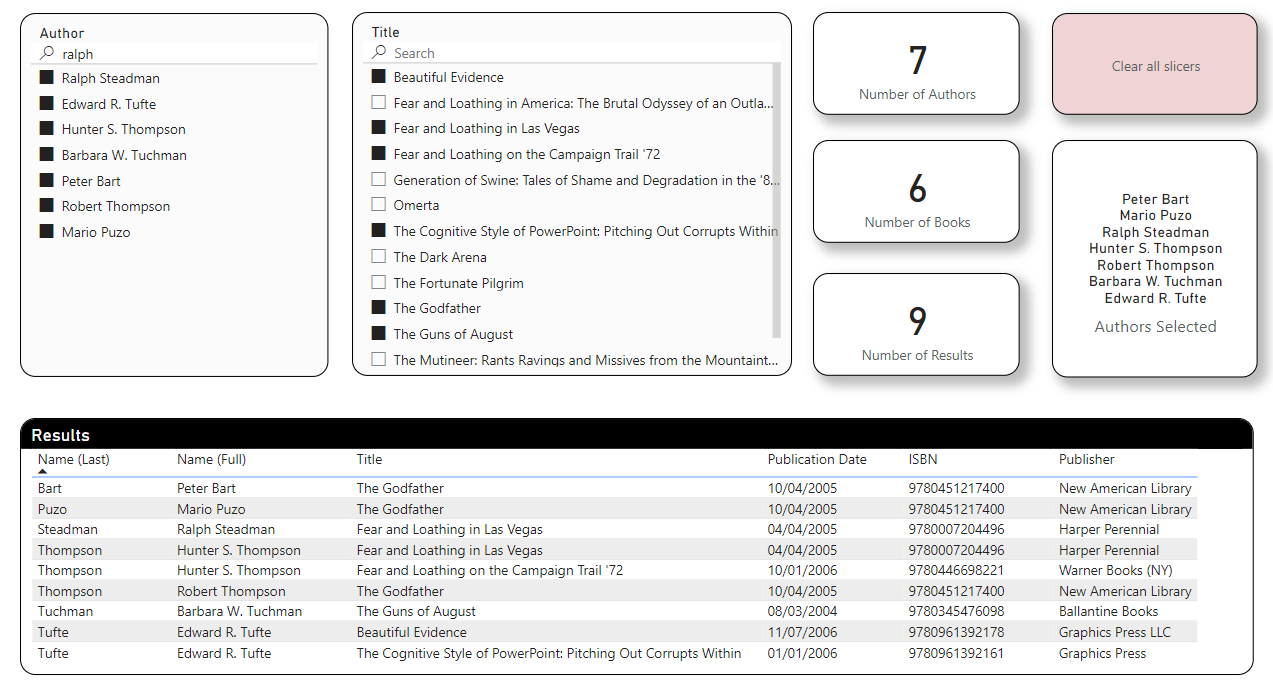
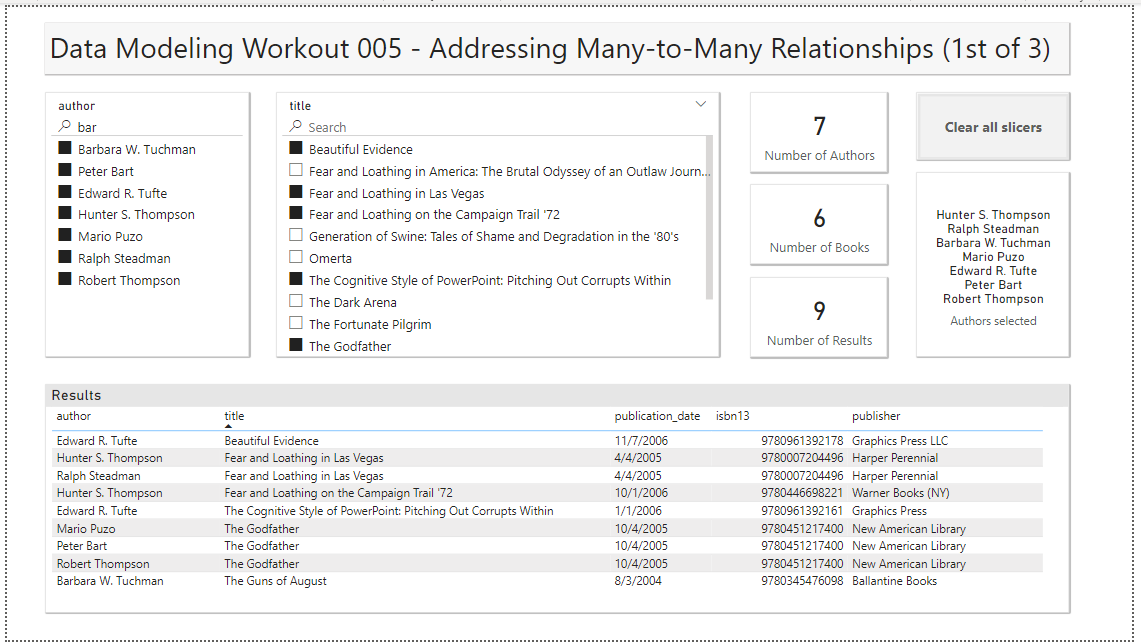
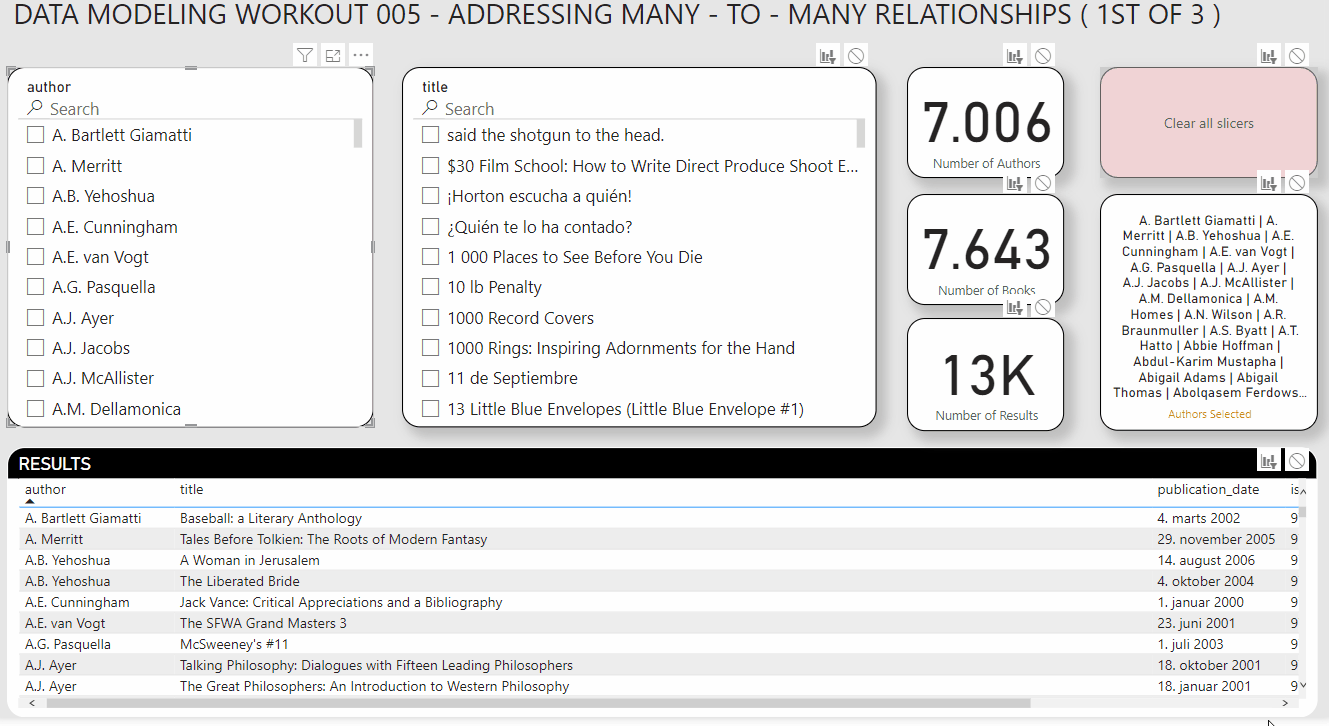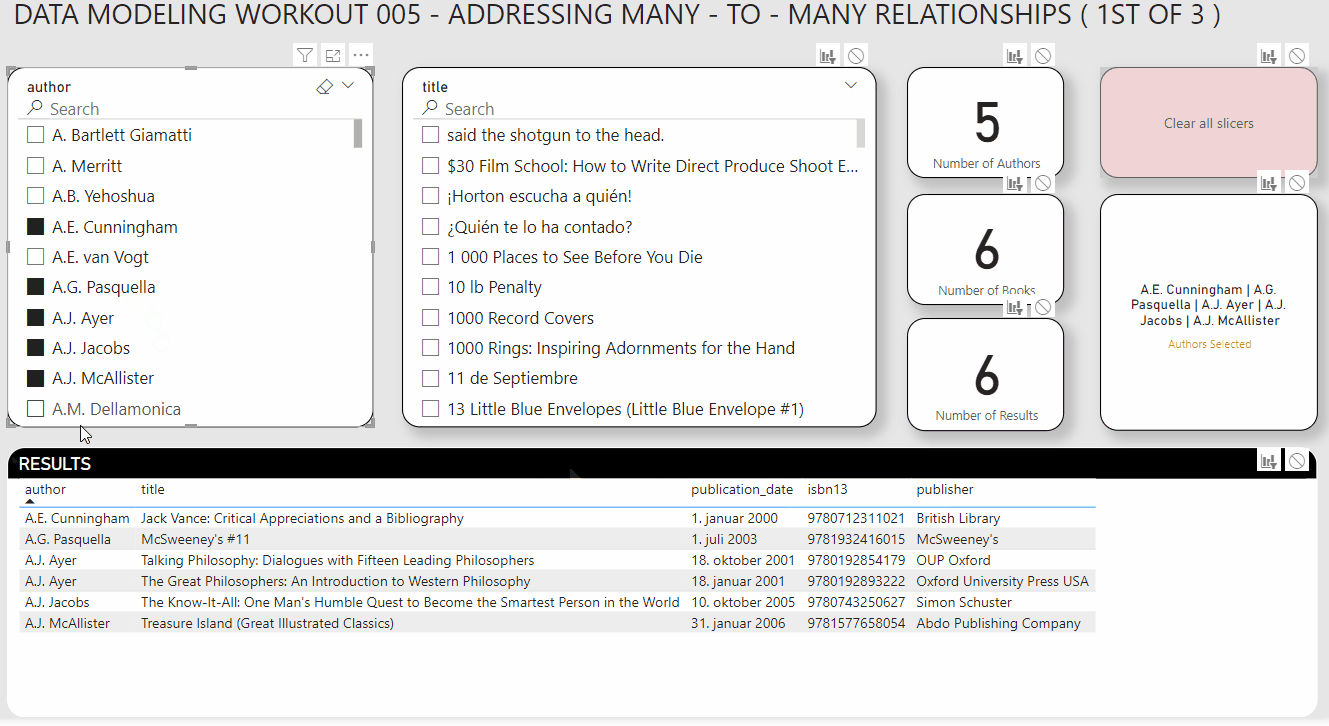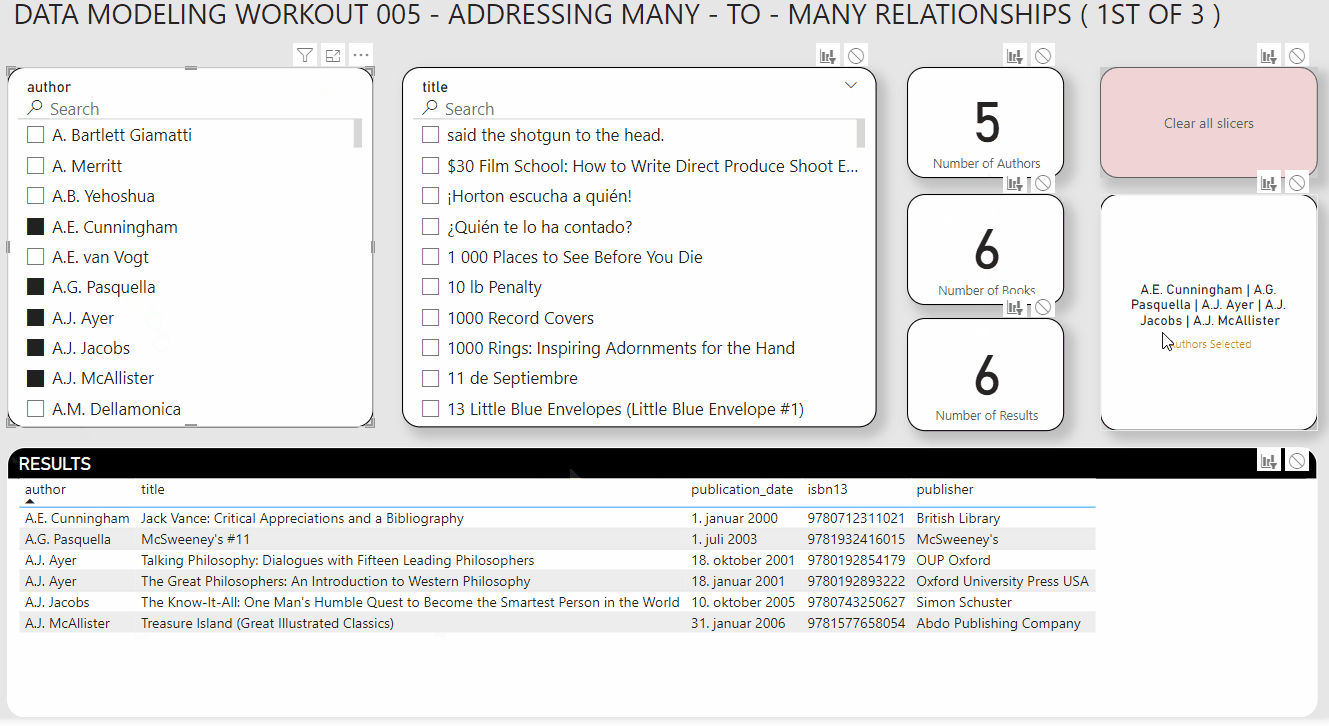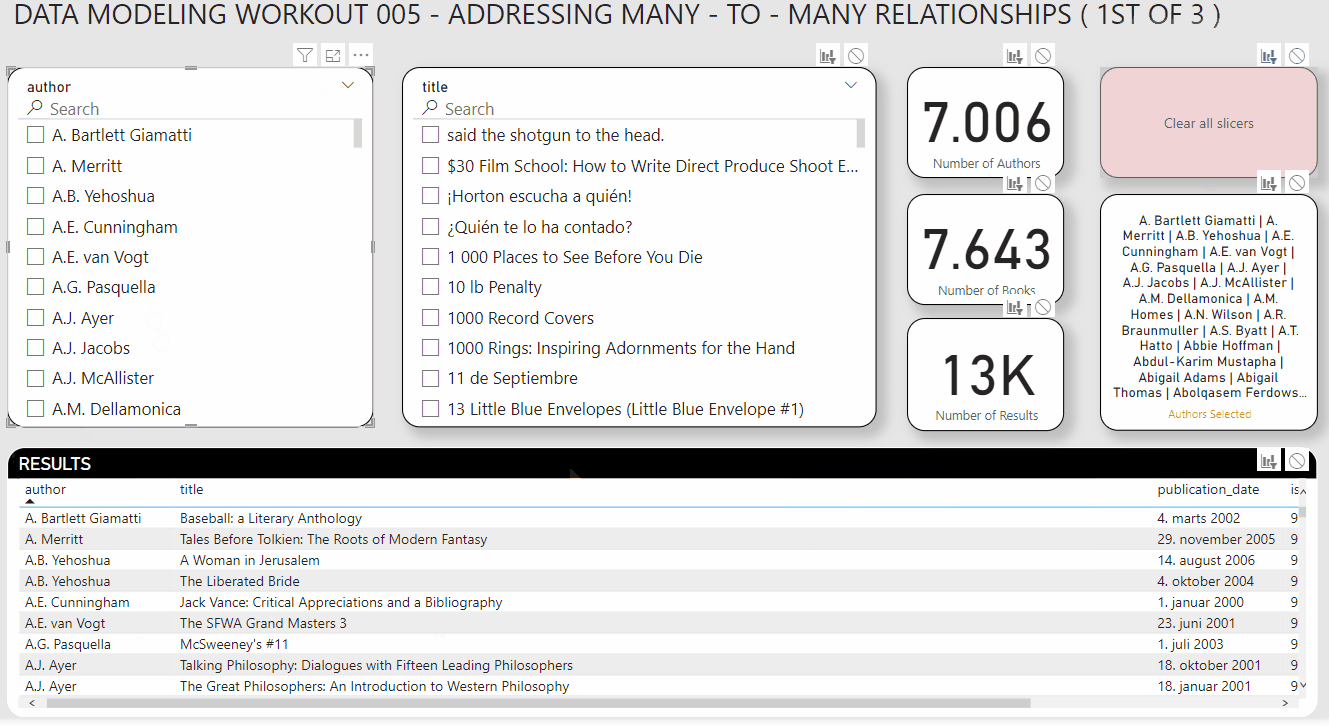
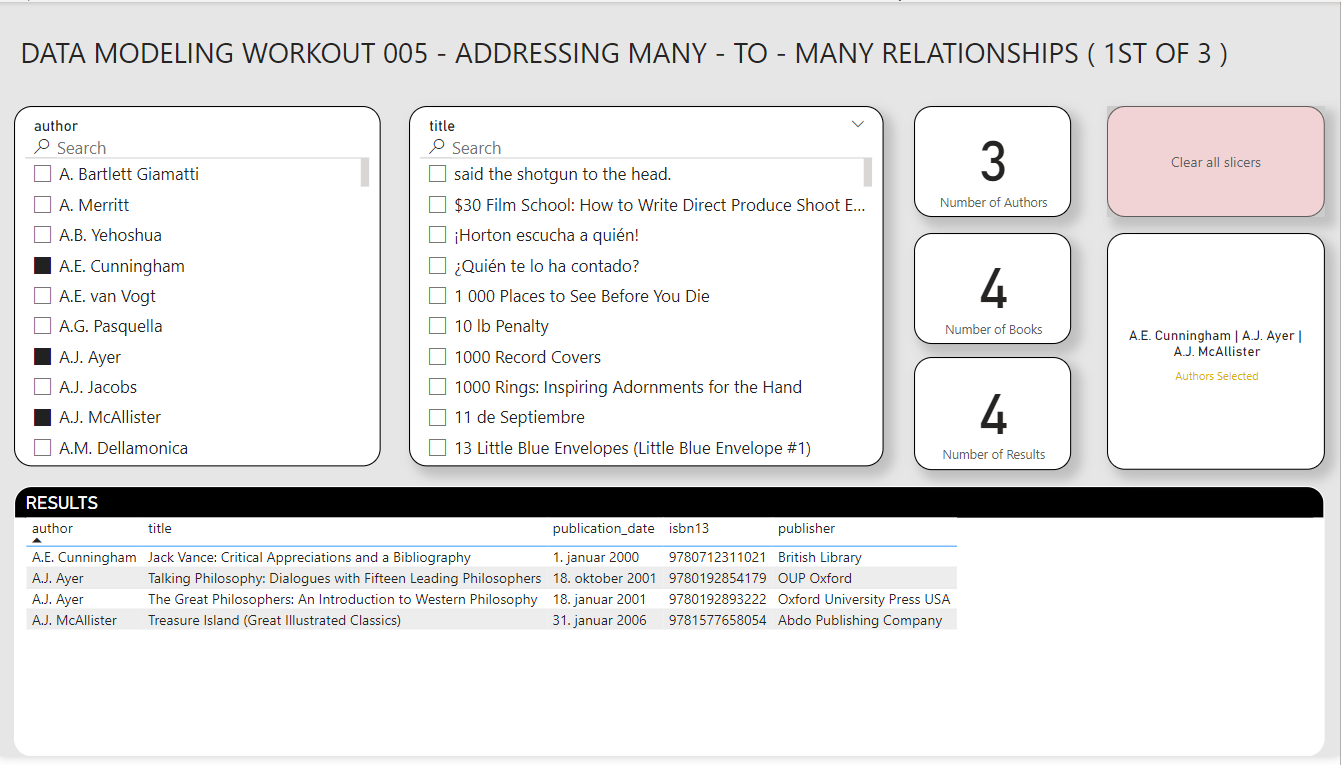
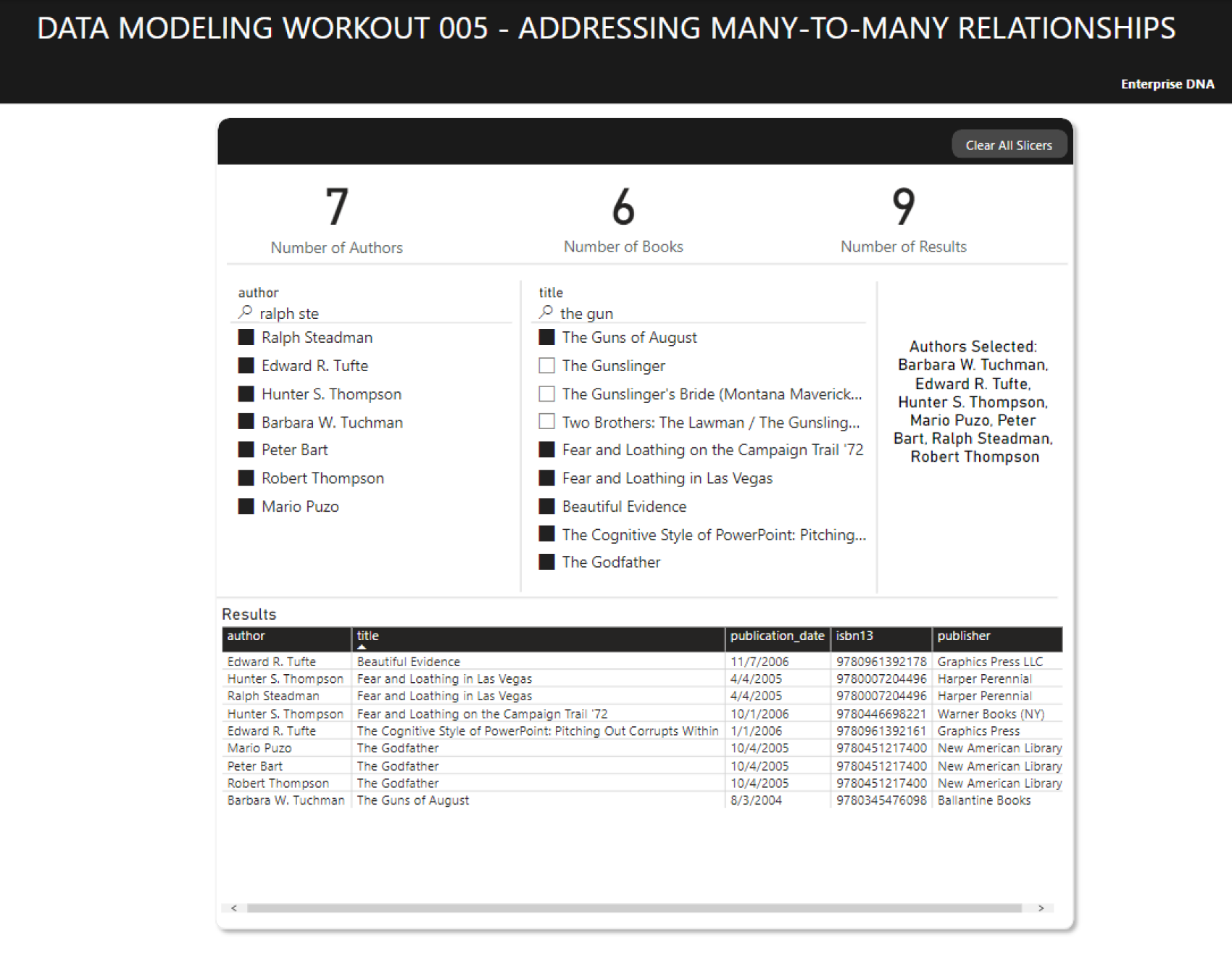
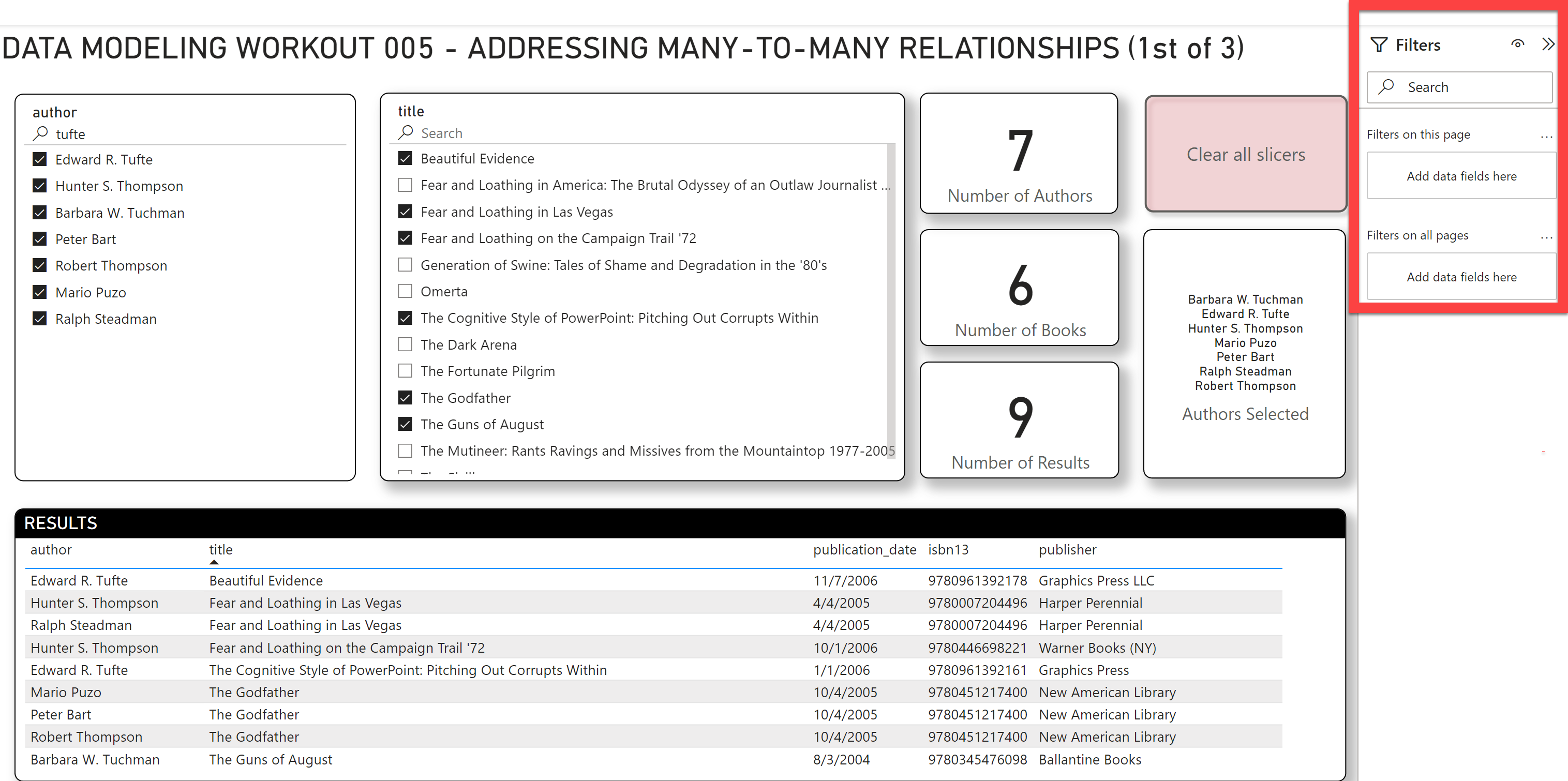
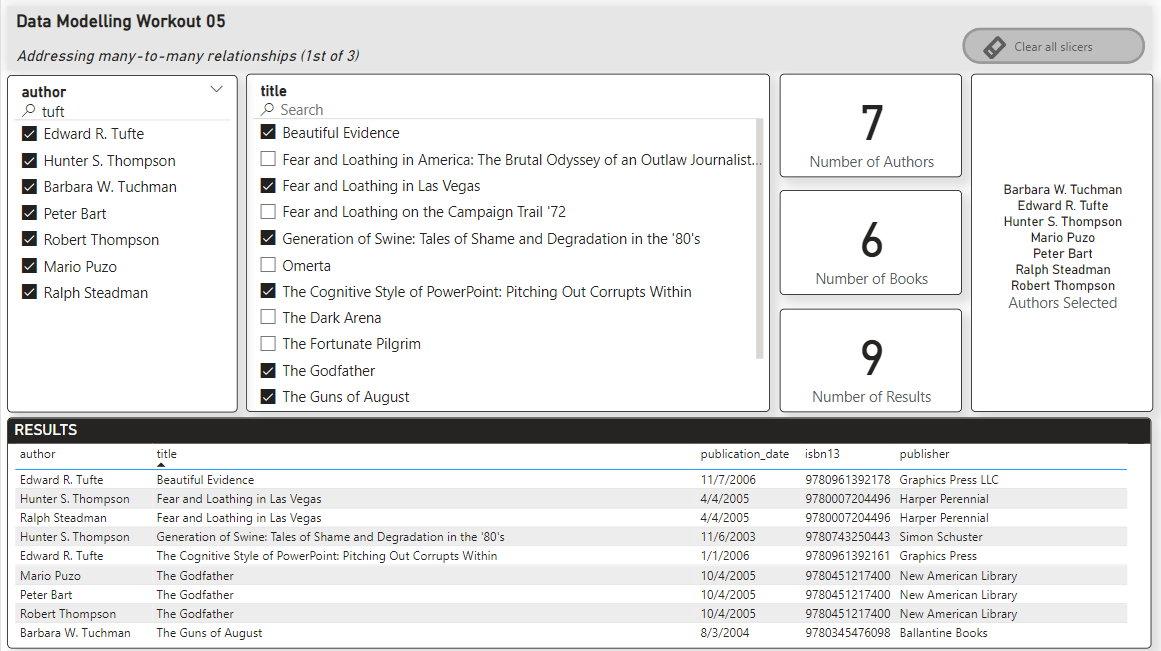
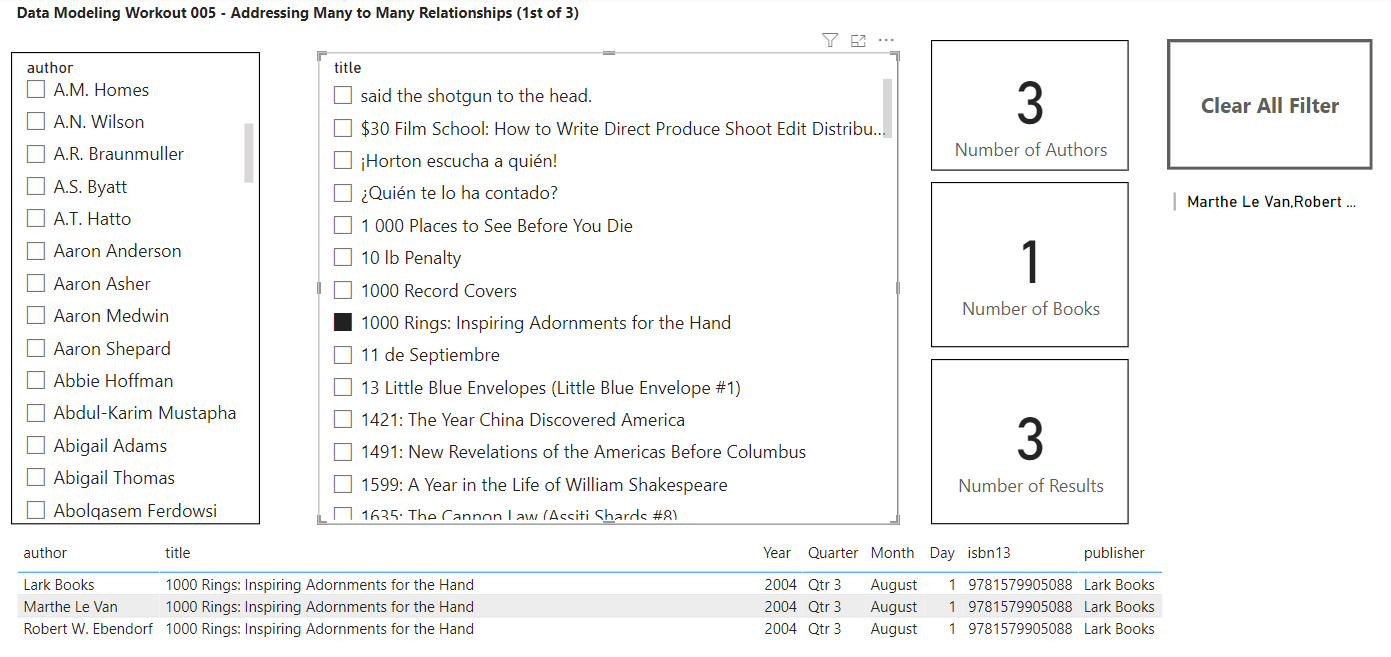
So, your task for this workout is to re-create the report below, using:
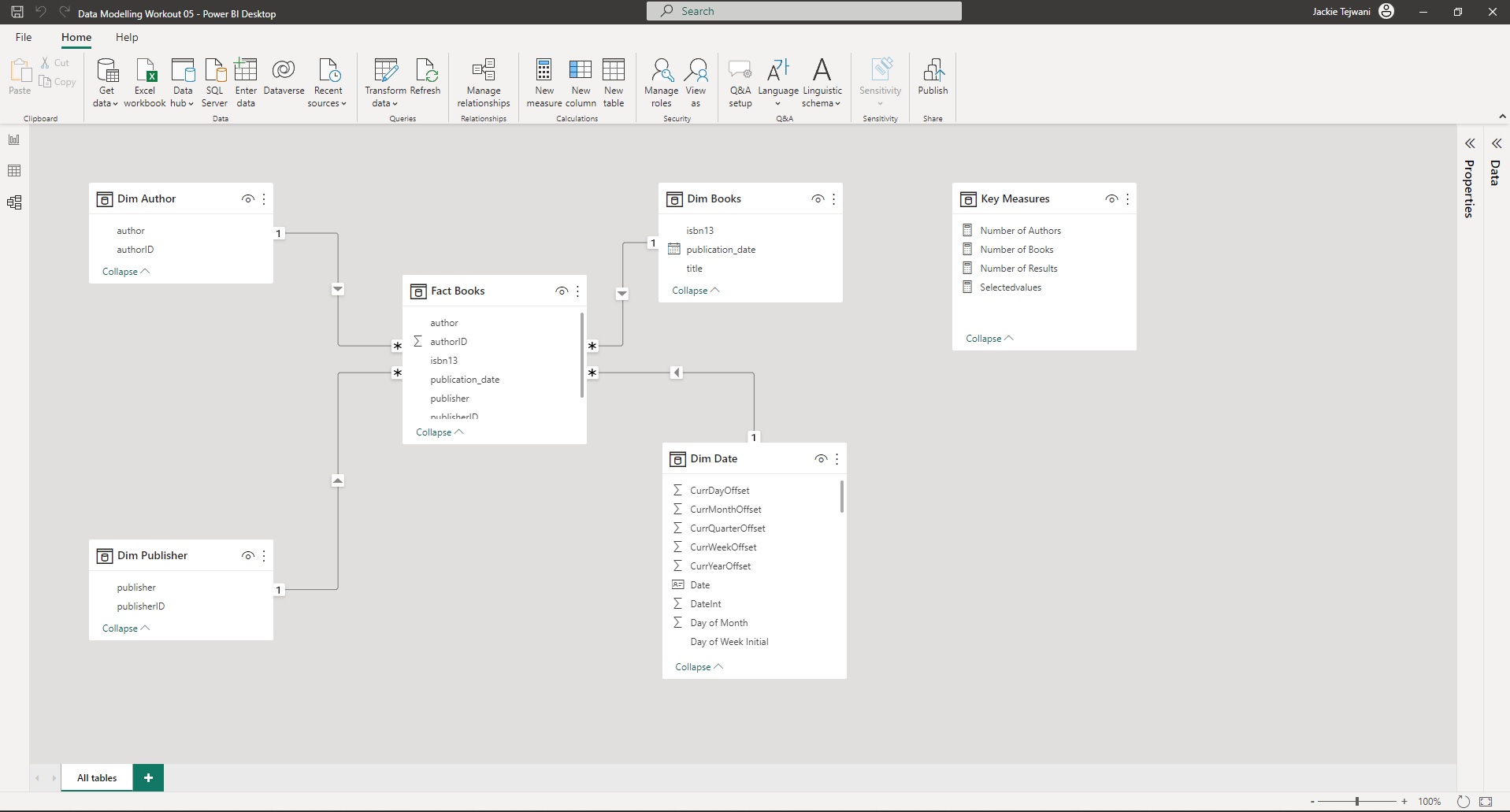
![]() Only one-to-many relationships, no bidirectional relationships
Only one-to-many relationships, no bidirectional relationships
![]() Only the following simple DAX measures for the card visuals counting number of authors, number of books and number of results:
Only the following simple DAX measures for the card visuals counting number of authors, number of books and number of results:
Number of Authors = DISTINCTCOUNT( Books[authorID] )
Number of Books = DISTINCTCOUNT( Books[isbn13] )
Number of Results = COUNTROWS( Books )
Note: Use isbn13 as the unique identifier for books
Use any DAX you like for the card mirroring the authors selected in the slicer
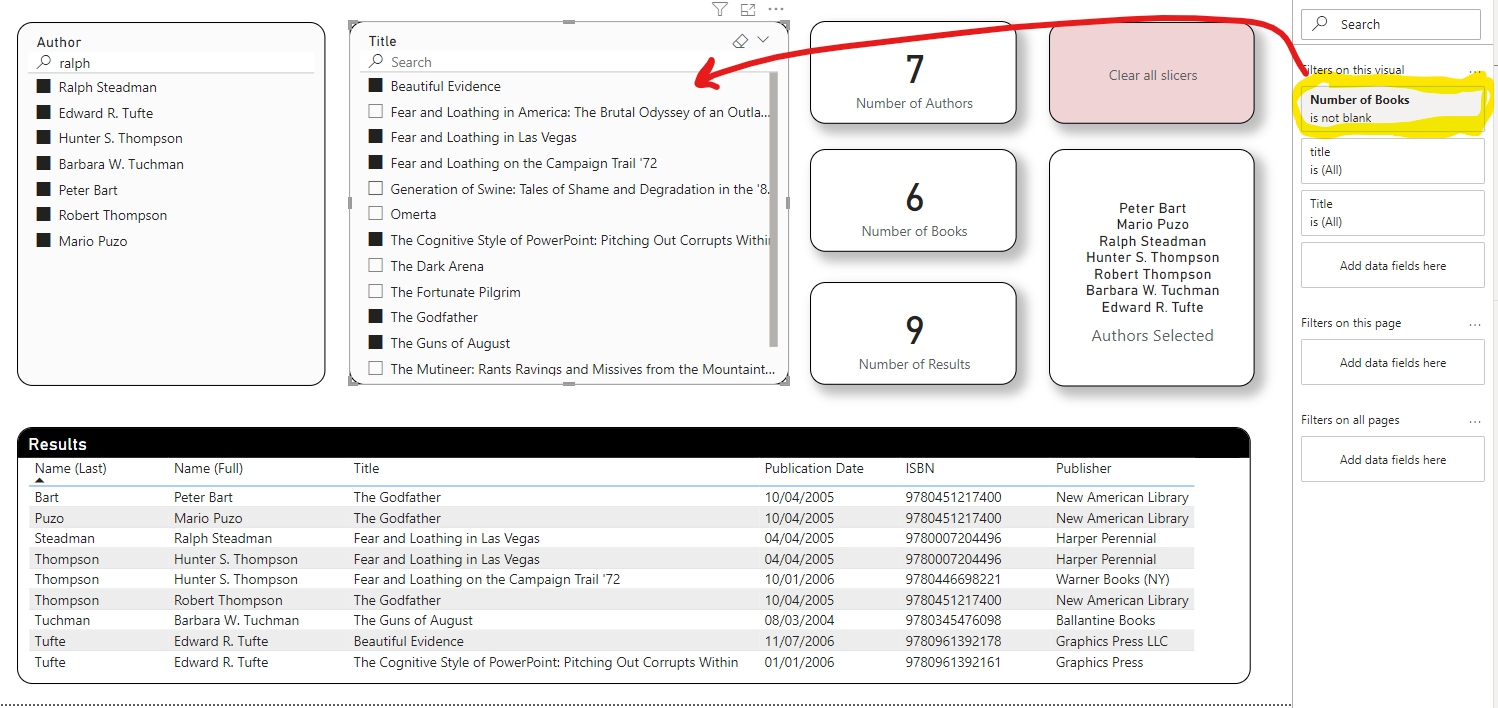
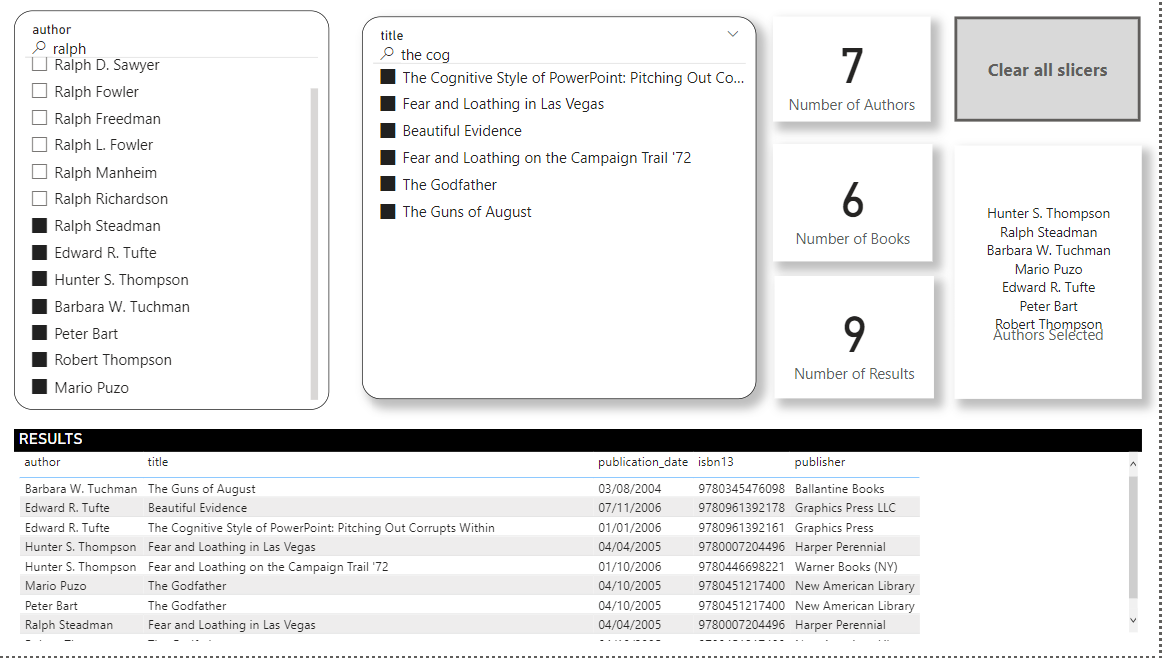
Your slicers also have to synch properly (i.e., when you select authors, the title slicer should filter to show only the books associated with those authors, or when you select titles it should filter the authors slicer to show only the authors associated with those selected books).
Also add text search capability to each of the slicers, per the screenshot below.
For your Dates table, use the Enterprise DNA Extended Date Table. The code for the table is available here:
eDNA Data Table Code
Other than those requirements, model the data in whatever way you think best.
Here the screenshot of the results you want to achieve:

And here’s your dataset:
Data Modeling Workout 005 - Books.csv (1.5 MB)
I will post my solution, next Sunday, May 14. Please be sure to hide or blur your results when you post your solution. Good luck!