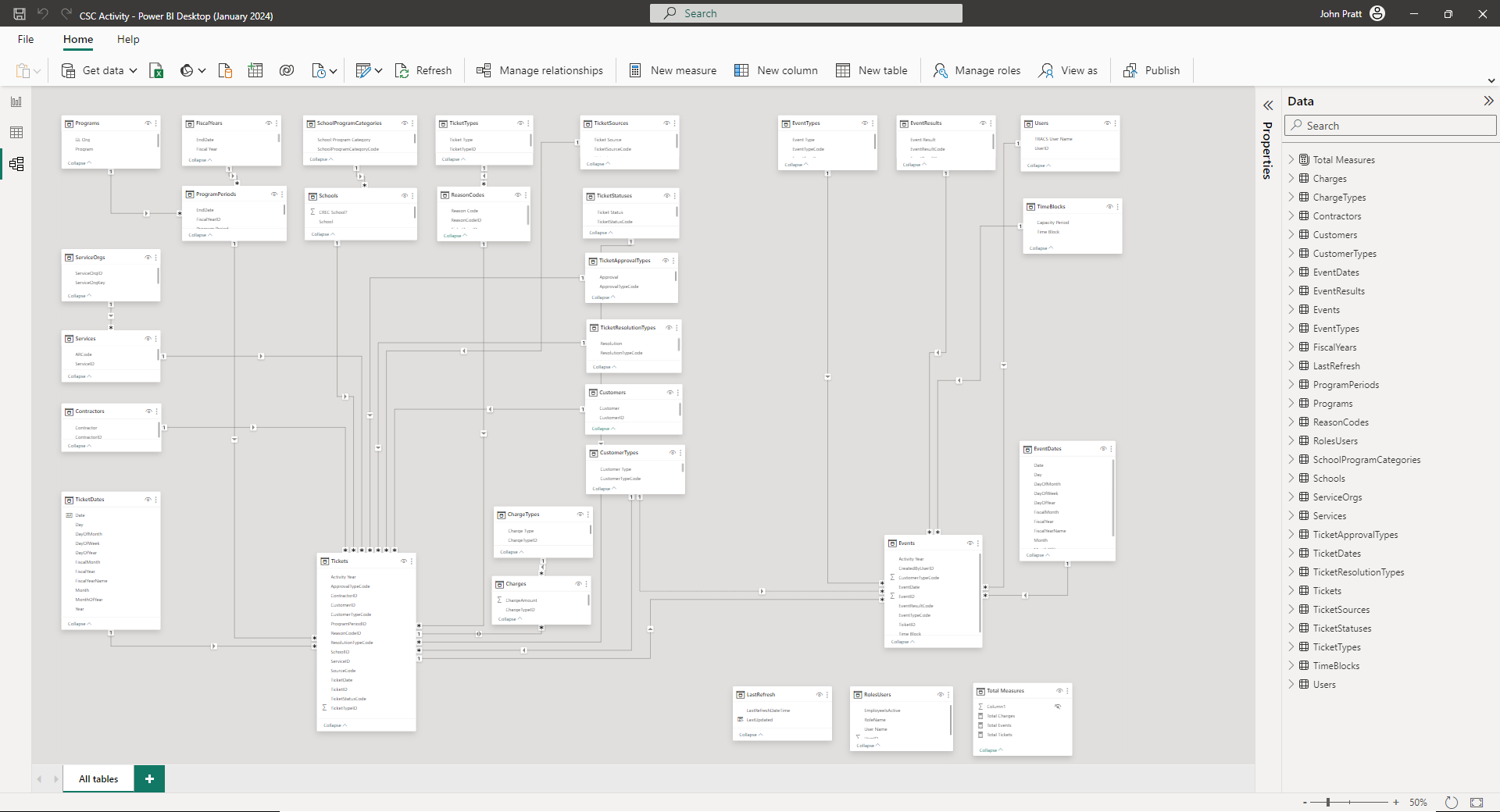
The data model for the Power BI report for the Transportation call center ticketing system I built is attached. I got it as zoomed in as I can while including everything. A couple notes about it:
There are 2 Dates tables, one for tickets on the left and one for events on the right. I did try to use one table with inactive relationships and it just didn’t work for everything I needed.
You will note some tables about Charges and Charge Types in the middle-bottom. I actually turned the ticketing system into a billable services management system back in 2016. That is a whole other topic .
Events are linked to tickets by design (more below) but are generally separate in the data model. I replaced an initial data warehouse with this one report, and got 10 times the functionality with a tenth the effort.
Events from a data standpoint are actually exactly what they sound like - things that happened on a given date and time. By “under tickets” I mean that they are child records, and every ticket gets at least two - a Created and a Completed system-managed event. In between, users can log emails, phone calls, and other actions. There are also system events like “Approved” and “Denied” which are system-created based on user action.
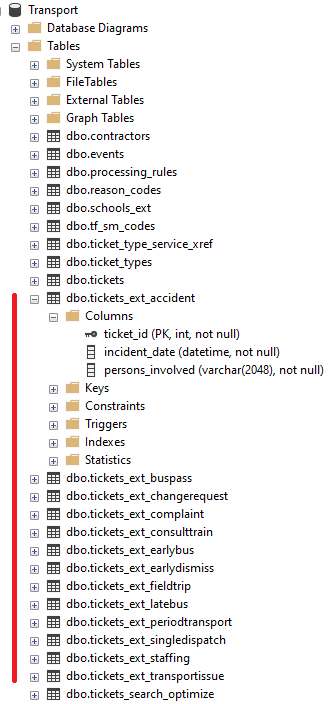
I have extended (read: custom) info in the underlying system as shown below (tables with the red line next to them). If I wanted to analyze tickets by the custom info, I would import the extended table data into the data model as a fact table linked to Tickets by ticket_id and then create measures and visuals specific to that ticket type (i.e. Accidents, Field Trips, etc.).
So interesting @jpratt, thanks for sharing your model!
You’ve done a lot with that model! It’s great to see. I see it’s in the Transportation domain. By coincidence, that’s the context in which I’m working too: an IT service delivery team for a transportation agency.
If you wanted to analyze tickets by that info, you said you’d import the extended (custom) info into the data model. Wouldn’t you then run into the situation I’ve tried to avoid: slowing the refreshes and performance of your existing, standard analyses that I assume must be robust and snappy?
That’s why I’ve wanted to segregate the refreshes of the extended tables by having them in a separate model except when they’re needed. Would you do that? Would you do it as Heather has proposed?
For Power BI in the cloud (i.e. the service), very large data sets/models, and/or if frequent (i.e. hourly or more often) refreshes are needed, what Heather is suggesting is what I would do. The custom, or extended, data aligns with an extended data model. There is also an added benefit of being able to isolate any one extended data refresh for optimization, testing, etc. That organic alignment will result in easier maintenance and adaptation of the model over time.
For example, further customization of one of the extended ticket types in the source system would only require modifications of the associated extended data model/refresh, leaving everything else alone. Coupled with a workspace app binding all related reports into one UI, this is an extremely adaptable solution design.
For my situation, I am working with Power BI Report Server on-prem mostly, and only need nightly refreshes of the data models. I do not use Direct Query on-prem primarily because time intelligence does not work with it and secondarily because it may have a performance impact on the report and/or source system. In addition, on-prem does not support shared or multiple datasets.
At this point, I have 788,000+ tickets and 2.7 million+ events in my data source. My data model refresh takes 1 minute, 4 seconds running at 1 AM . If I needed any extended data in my particular model, I would just add a new mini-fact table (snowflake style) within the existing data model.
Technically, the overall reporting data structure is the same for both approaches - a snowflake schema. The actual mechanics of surfacing the data differ, but the measure and visual creation would effectively work the same or very similarly.
It’s not incremental! Part of the performance may be that the Power BI Report Server installation is on the same SQL Server as the source data. I have another large data model loaded from our ERP system on a different DB server that takes 2 minutes 22 seconds.
By “on-prem” I meant Power BI Report Server. If you are using the Power BI cloud service, your data source is on-prem, and you are using the premium data connector to access the data from the service, you should be fine with multiple datasets. We don’t have premium licensing, so even though we do have the Power BI service for one of our divisions, I cannot access on-prem data from it. Like running a marathon with both hands tied and one leg out of commission.
 .
.