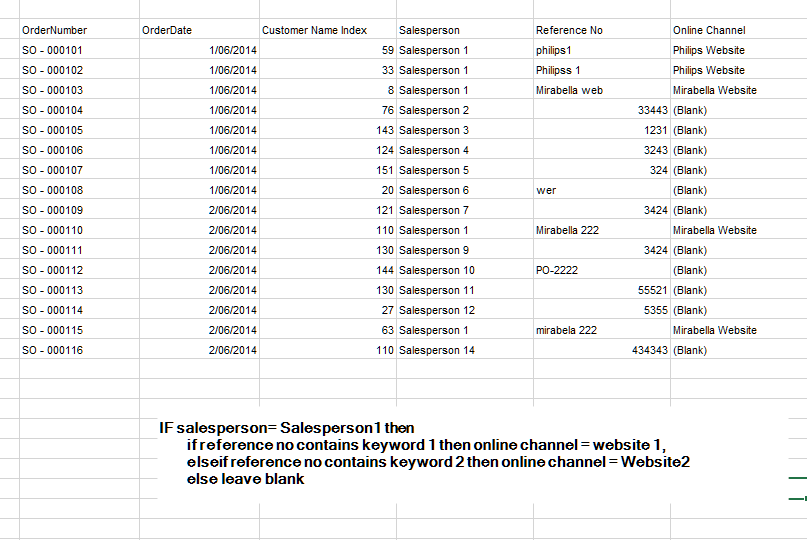
I’ve got a field called reference no which is a free text field and based on the reference no field I am trying to categorise them into respective website sales. My problem is my sales fact tables contains sales from other sales channel as well which are not from website and I want to leave them blank.
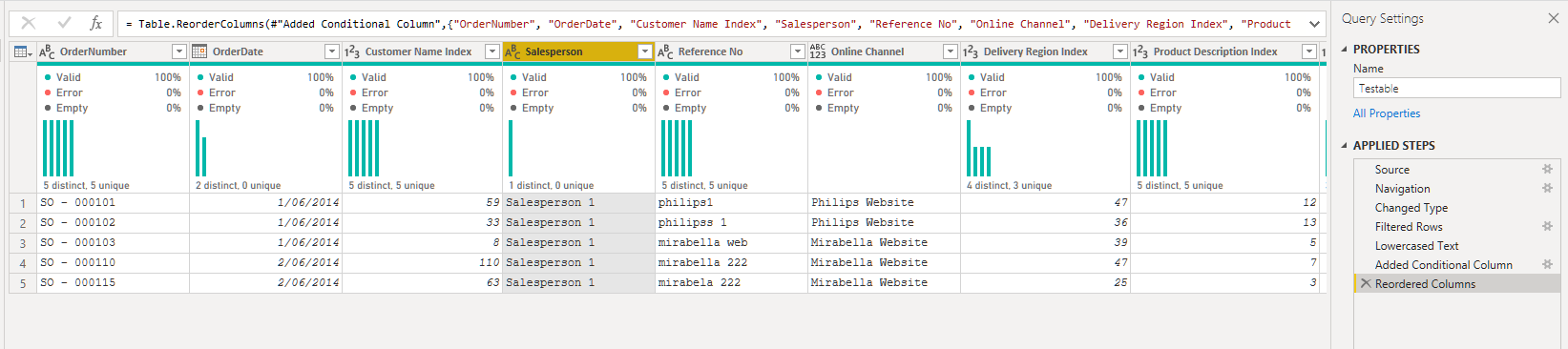
I tried filtering via one salesperson and then creating a conditional column and managed to get the channel but unable to populate all the sales data from other sales person.
So just wondering how can I solve this? And what is the best practice regarding this? Is it better to modify the actual reference no field or create another conditional column for that particular grouping.
I have attached the pbix file for reference
The image below is what I’m looking for.
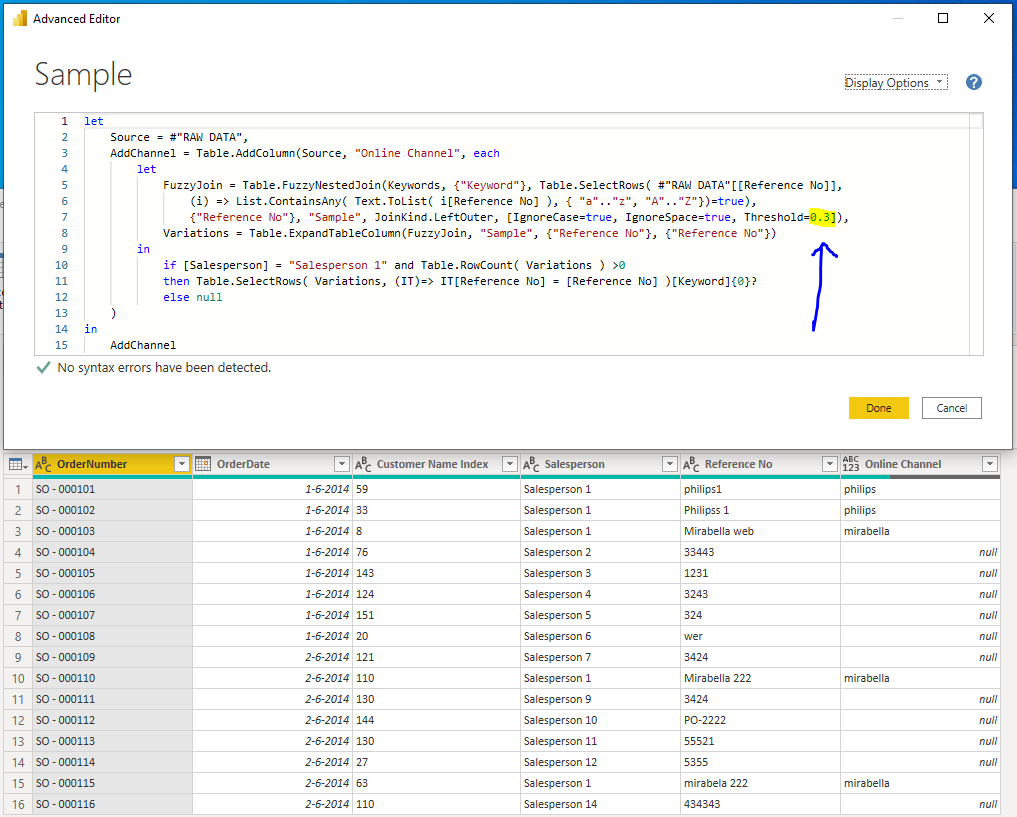
performed a FuzzyNestedJoin on Keyword and tinkered with the threshold value…
Now Fuzzy matching is a bit of a black box, so you might have to adjust the threshold level in your production model. To “Show” you the results I’ve included a KeywordsFuzzyResult query. (Review the documentation via the link above.)
Thank you for your time and effort. Really appreciate the help
I looked everything about fuzzynestedjoin and good with that. But I couldn’t evaluate what is the rationale behind this marked code. Would you be able to help with that a bit?
One more question though, I’ve got like millions of rows on this sales table, will it affect the performance level as we are doing joining on each row level?
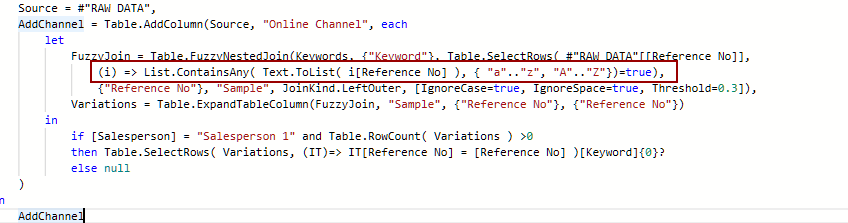
Sure. I’ve moved the highlighted portion to the top, amended it (although its function remains the same) and added a comment which explains what it does. On performance. you’ll have to test and judge if this is acceptable…
let
// Only keep rows that aren't numbers and load that table into memory.
BufferReferences = Table.Buffer( Table.SelectRows( #"RAW DATA"[[Reference No]],
each ( try Value.Is(Number.From([Reference No]), type number) otherwise false )=false )),
Source = #"RAW DATA",
AddChannel = Table.AddColumn(Source, "Online Channel", each
let
FuzzyJoin = Table.FuzzyNestedJoin( Keywords, {"Keyword"}, BufferReferences,
{"Reference No"}, "Sample", JoinKind.LeftOuter, [IgnoreCase=true, IgnoreSpace=true, Threshold=0.3]),
Variations = Table.ExpandTableColumn( FuzzyJoin, "Sample", {"Reference No"}, {"Reference No"})
in
if [Salesperson] = "Salesperson 1" and Table.RowCount( Variations ) >0
then Table.SelectRows( Variations, (IT)=> IT[Reference No] = [Reference No] )[Keyword]{0}?
else null
)
in
AddChannel
.
Only alternatives I can think of are:
Using the AI text analytics but that requires Premium OR a dedicated capacity workspace (don’t know if that’s an option for you, I have no experience with that myself)
Create a list with all possible variations to write the channel name (yourself) and leverage that instead so you can avoid the merge.
Hi @Melissa ,
Thank you for getting back again. Unfortunately it didn’t work. The data model kept on loading and didn’t do anything for around 2 hours.
I’ll am leaning towards trying out the solution no 2
" * Create a list with all possible variations to write the channel name (yourself) and leverage that instead so you can avoid the merge.".
Sorry to be a pain but I understood creating the list part but what would be the next step beside merge. Do you mean replacing the values based on the list?