I have a rather large report with sources from numerous systems. The company went through some acquisitions and we are trying to view our consolidated data within Power BI.
We have System A which will provide a list of all Corporate Names. System A will also hold all of the account information for Company 1. I connect to system A via SQL Server and pull in whatever I need. My other source of Account information is from an excel sheet provided by Company 2. This sheet gives me the Account Name as well as the ID of the Corporate Name from System A (where applicable - not all accounts from Company 2 will have a Corporate name. Some from Company 1 do not have a Corp name either)
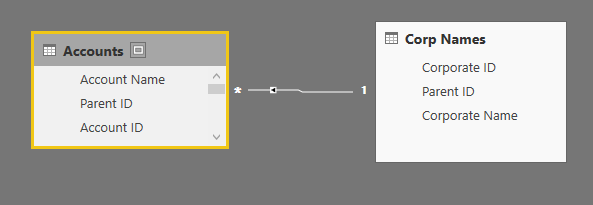
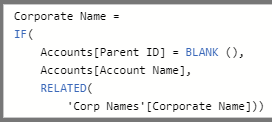
I cleaned up the information and appended the 2 Account queries to act as one. I set a relationship on column Parent ID, which exists in my new appended query as well as the Corporate Name query. I need to be able to see all Corp Names and not have blanks roll up together, as such, I added a new conditional column to the Account query to pull in Corp Name from my Copr Name table and use Account name from Account table if there was no Corp Name. Column is as follows:
I now have a Corporate Name column with my accounts that I can use for my visuals (Accounts[Corporate Name]) Problem is, I still have a significant amount of BLANK Corp Names there. When I back track through, the Corp Name exists in the Corp Name table (Corp Names[Corporate Name]), the account has a parent ID (Accounts[Parent ID]), but the value is still blank.
Any thoughts on what would cause this? I refresh the data and get the same results, sometimes with different accounts (EnterpriseDNA may show up blank, then after a refresh, its OK, but Microsoft is now blank)
Finding it hard to visualize this actually as there’s a bit to it.
Any reasons you can’t merge this in the query editor. This sounds to me like something you should do there rather than here. Then get rid of duplicated.
Pictures of the model, calcs, results would be helpful as hard to imagine everything as per the above at the moment
SLX Accounts and ANC Accounts have the following columns and are appended as a new Query, Accounts
Corp Names has the Corp Name and Parent ID (link to accounts)
What I need to ultimately do is create a new column in Accounts that has the Corporate Name. if there is no associated Corporate Name in the Corp Names table, I would like the column to show the Account Name. I accomplished this by adding a column to Accounts
What happens is when I now display this information in a table on the canvas, I will have some accounts with a blank field in Accounts[Corporate Name] (blacked out customer names), even though there is an account name and a parent ID. note, I am not using the Corp Names[Corporate Name] value here, I am using Accounts[Corporate Name]
When I check my source, that Parent ID has a corporate name. So I’ll make note of the account and refresh my data. This may fix it or may not, I have seen both, but then leaves another account with a blank name that previously was OK. It is almost as if not all rows are making it to the model from the query (about 62K rows)
I think I tracked this down to a data model/source data issue. The source data has a join that provides a lot of duplicate results which were then being removed in the query editor. Giving different results on other columns in the table.
Wound up finding out that the front end application for the data source also has a bug that overwrites/removes values in the fields we were pulling, so none of the data would be valid anyway.