This may have been covered elsewhere if so please just post the link.
The dateset has two tables a codes table and an increment table.
Code Table
Code
Start
End
WS
27/08/2020 00:00:00
27/08/2020 01:17:53
RF
27/08/2020 01:17:53
27/08/2020 01:51:18
AC
27/08/2020 01:51:18
27/08/2020 02:36:16
FV
27/08/2020 02:36:16
27/08/2020 02:36:54
MM
27/08/2020 02:36:54
27/08/2020 02:37:21
NN
27/08/2020 02:37:21
27/08/2020 02:38:09
TR
27/08/2020 02:38:09
27/08/2020 02:38:49
WS
27/08/2020 02:38:49
27/08/2020 02:40:03
WS
27/08/2020 02:40:03
27/08/2020 02:42:00
Increment Table
Date
Increment
27/08/2020 00:00:00
12
27/08/2020 01:18:53
12
27/08/2020 01:53:18
12
27/08/2020 02:37:16
12
27/08/2020 02:37:54
12
27/08/2020 02:37:54
24
27/08/2020 02:38:09
12
27/08/2020 02:39:49
12
27/08/2020 02:41:03
24
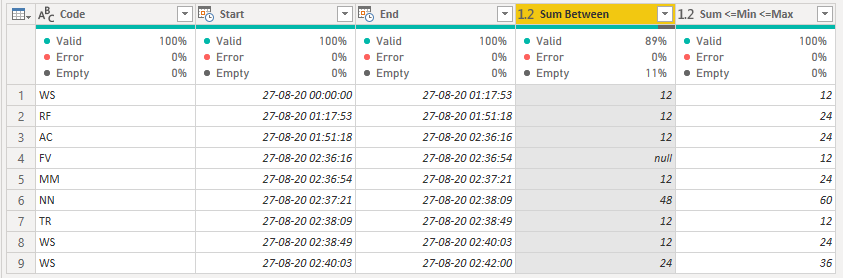
What i would like to achieve is a final table that based on the [Codes Table] (start time) and (end time) goes through the entire [Increment Table] and returns a sum of the increment column for each row in the [Codes Table].
.
Note. If in your actual scenario your tables are very large consider adding Table.Buffer, so you’ll load the Increment table into buffer memory once and use that repeatedly in Table.SelectRows.
Hi @haroonali1000. I’m an M code newbie, and could only get part way there, but wanted to post my work-in-progress in case it helps. The function works properly, I just haven’t yet found the correct syntax add the function output as new column in the [Facts] table. Hope it helps. Greg eDNA Forum - Creating a Fact Table.pbix (22.2 KB)
I figured you’d have a solution posted before I could learn enough, and surprise surprise, you’re first (again ). Thanks for the encouragement and the pointers … I’ve updated my code (as I wanted to learn from the best ) and it now works … @haroonali1000 I hope this helps.
Greg eDNA Forum - Creating a Fact Table.pbix (22.5 KB)
P.S.: Here’s the M code [I should have added mine in the last post … sorry])
fxSumIncrementsInPeriod =
(my_start as datetime, my_end as datetime) =>
let
Source = Increments,
FilteredIncrements = Table.SelectRows(Source, each [Date] > my_start and [Date] <= my_end ),
SumOfIncrements = List.Sum(FilteredIncrements[Increment]),
Output = SumOfIncrements
in
Output
Facts =
let
Source = Codes,
AddSumOfIncrementsColumn = Table.AddColumn(Source, "SumOfIncrements", each fxSumIncrementsInPeriod([Start], [End])),
Output = AddSumOfIncrementsColumn
in
Output
Let’s pay it forward with @Greg 's awesome fx.
So loading the table you want to filter, that’s the first argument inside Table.SelectRows can have a positive effect on Query performance, therefor I wrapped the nested Source step in Table.Buffer
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("dZGxCoUwDEV/5ZFZIU1bW7M9BDcdVHQo/f/f0Bd5g62BTOdwlpuU4FihAQotxpaQ8IPIcgU1bAJ7C7lJsIyKLKm/RJTkOyjySYltx6aTZNwV+UK9k2SaFFnRwGQkmWdFVjQy9pJsiyJfqLuTauS/LKm7prdacsuK0u9bOZ8=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Code = _t, Start = _t, End = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Code", type text}, {"Start", type datetime}, {"End", type datetime}}),
fxSumIncrement = (my_start as datetime, my_end as datetime) =>
let
Source = Table.Buffer(#"Increment Table"),
FilteredIncrements = Table.SelectRows(Source, each [Date] >= my_start and [Date] <= my_end ),
SumOfIncrements = List.Sum(FilteredIncrements[Increment])
in
SumOfIncrements,
InvokeFunction = Table.AddColumn(#"Changed Type", "Sum Between", each fxSumIncrement([Start], [End]), type number)
in
InvokeFunction
.
What can also help is only loading the columns into memory that you need, then you would get something like: Source = Table.Buffer(#“Increment Table”[[Date], [Increment]])
or if your actual Increment Table could contain duplicates: Source = Table.Buffer( Table.Distinct(#“Increment Table”[[Date], [Increment]]))
You’re much too kind @Melissa, but thanks. I went really fast and didn’t check the [Codes] data too carefully, but it looked like the end of one period was the same as the start of the next; as this is just a sample, probably no worries, but check the comparison and adjust as necessary.
Greg
@Melissa@Greg thank you both for your input was much appreciated.
I experimented with the function and my data set and saw some interesting results.
I managed to get the function doing what i wanted and working with a small sample however when i used an actual dateset the performance absolutely tanked to a point where it was unmanageable.
I was working with roughly 40000 rows in my increment table and around 3000 in my codes table this didn’t seem like much but caused PQ some issues so having to explore other options.
 ). Thanks for the encouragement and the pointers … I’ve updated my code (as I wanted to learn from the best
). Thanks for the encouragement and the pointers … I’ve updated my code (as I wanted to learn from the best  ) and it now works …
) and it now works …