I have a fact transaction table, which I’ve narrowed to 3 columns: account name, transaction date, and sales quantity. See attached pbix.
I need to find a way to create slicers that separate the list of accounts into stalled vs active as well as multi-order vs single-order.
My initial idea was to create a separate dimensional table that contains a unique list of account names plus 2 additional columns, one for each of the following designations:
(1) Stalled vs active: if the client has made a transaction in 45 or fewer days, it is active, otherwise it is stalled.
(2) multi order vs single order: if the account has made 2 or more transactions anytime throughout history (2 or more records on the fact transaction table), it is multi-order. If it’s made only 1 transaction throughout history, it is single-order.
If I can create this dimensional table using dax or M query, then I can create a relationship with the fact transaction table and start slicing and dicing the accounts by whether they are stalled, active, single order or multi order.
If there’s another way o create these slicers, such as incorporating it right onto the fact table, I’m open to it.
Thanks, Brian! Excited to see what you come up with. I’ve been working with a back end team on this for a couple of months and they haven’t been able to solve it with SQL. Hence why I’m looking for help from the enterprise DNA hive mind.
OK, there are two concepts key to addressing this question IMO: “Roche’s Maxim of Data Transformation” and “Junk Dimensions”.
Roche’s Maxim - here’s a slide from the talk I’ll be giving at this week’s Enterprise DNA Analytics Summit (“Addressing Granularity Mismatches in Power BI”) that lays out the key points of Roche’s Maxim. The article linked to the URL provided in the slide is one of the most important articles I’ve ever read regarding Power BI, and indicates clearly that this work should be done in Power Query or even further upstream in you data warehouse if possible.
The bottom line here is that all of this should be happening upstream of DAX, since none of these calculations/transformations are dynamic within the context of a reporting session.
Junk Dimension - In “The Data Warehouse Toolkit” (an essential book for your data analytics bookshelf), Ralph Kimball defines a “Junk Dimension” as:
“The grouping of typically low-cardinality flags and indicators. By creating an abstract dimension, we remove the flags from the fact table while placing them into useful dimensional framework.”
So, what I did here was:
created a temporary column in the fact table callled Today = Date.From( DateTime.LocalNow())
subtracted the Invoice Date from Today to get Days Elapsed
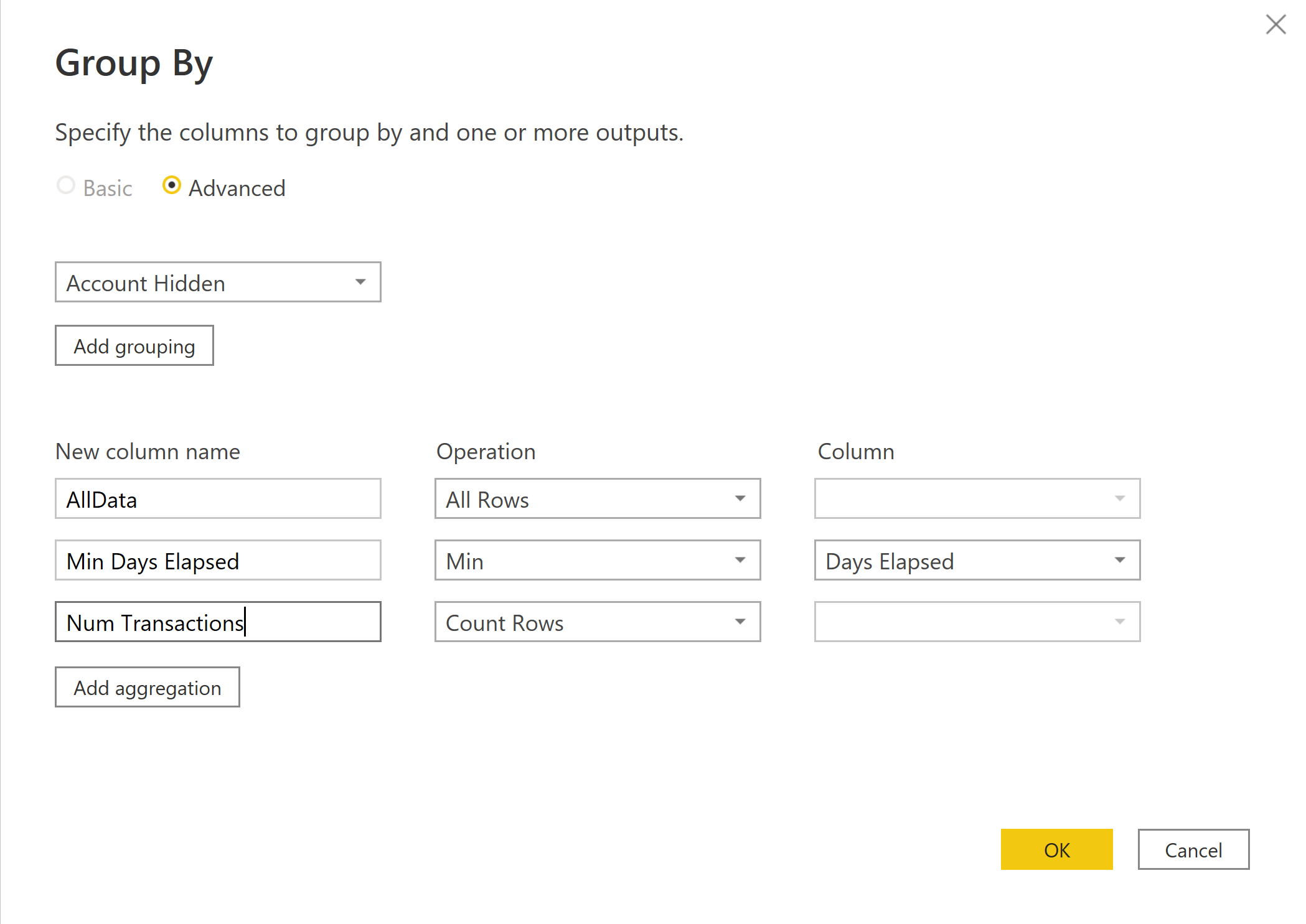
using the All Rows/Group By structure (I have a YouTube video on this exact topic if you’re not familiar with this approach), created the Min Days Elapsed and Num Transactions for each Account Number:
created Client Type, which = Single-Order if Num Transactions = 1, else Multi-Order
created Client Timing, which = Active if Days Elapsed <= 45, else Stalled
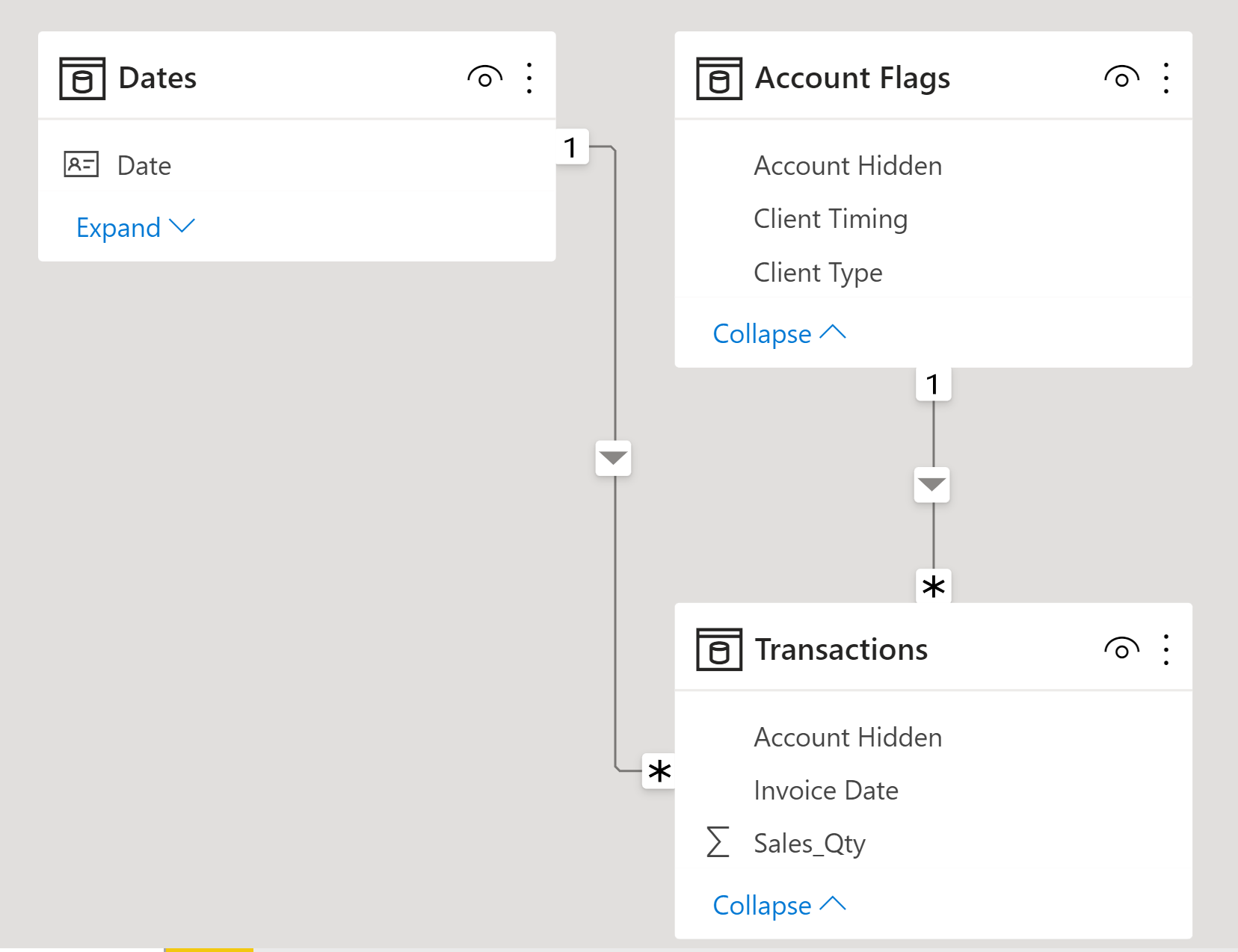
Then I duplicated the fact table, removed everything but Account #, Client Type and Client Timing, removed duplicated and created a 1:M relationship between this “Junk Dimension” and your original fact table based on Account #
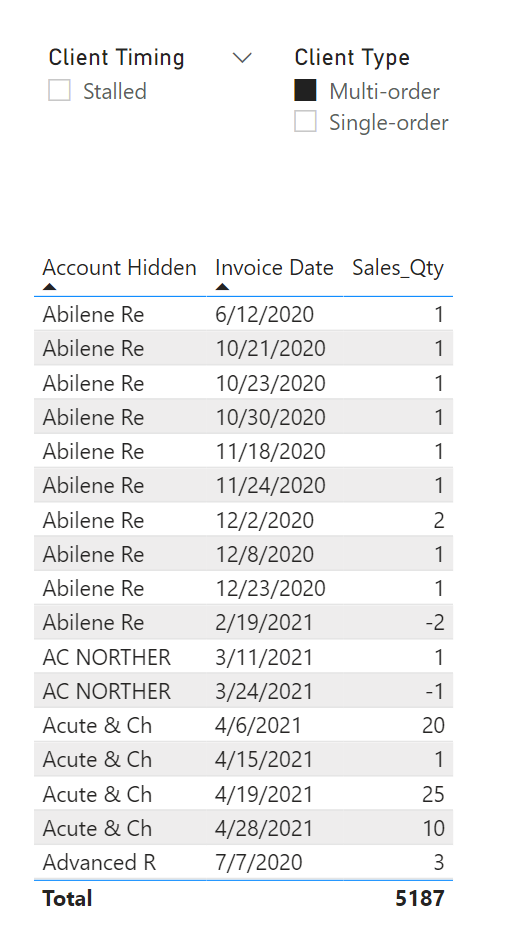
You can now easily slice on Multi/Single Order and Active/Stalled, per the screenshot below.
Just to complete the data model, I also added @Melissa 's extraordinary Extended Date Table, marked it as a date table, and linked it 1:M to the invoice date field in the fact table.
A great solution as always. I am eagerly waiting to watch your session “Addressing Granularity Mismatches in Power BI”. Just looking at the problem statement and thought it could be done in 3 ways by the order of precedence.
SQL
Power Query
DAX
For me, SQL solution was straightforward provided I have an environment :), so for these kinds of scenarios, simple SQL coding comes really handy.
You are in very good hands as you are a member of Enterprise DNA. I am preparing a course on SQL for Power BI users. To be honest, SQL becomes really easy if you have little experience working with Power BI. I hope that this course will be available to members by Feb 2022.
I totally agree with @hafizsultan - per Roche’s Maxim, if you have the ability to push this further upstream to the SQL level, that would be ideal. I just wanted to demonstrate how to implement the Junk Dimension approach, but that same technique can easily be applied in SQL.
As Hafiz also mentioned, we’ve currently got Feb 2022 lined up as “SQL Month” with Hafiz’s course on “SQL for Power BI Users” as well as one from @AntrikshSharma which is the mirror image of that course “DAX for SQL Users”. Tons of great new coursework coming in Dec. (announcement coming soon about a huge special content event in Dec) and in 2022. Stay tuned…
Thanks guys. Learning how to use Groupby is a total game-changer. I’ve been wanting to organize data in groupings like this since I started but never knew how until now. Thanks again!
BTW - terrific initial question. I think there are a lot of important issues that came out of this thread, and so late last night I cranked out a detailed YouTube video about Junk Dimensions that should be hitting the street next week (since most of our videos this week will be from the upcoming Analytics Summit…).