@supergallagher25,
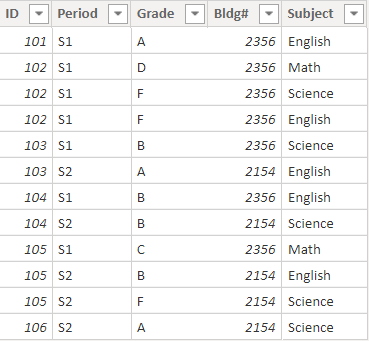
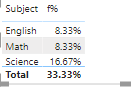
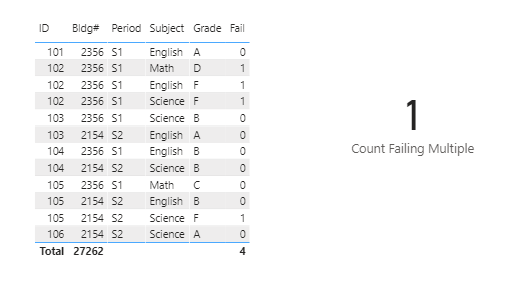
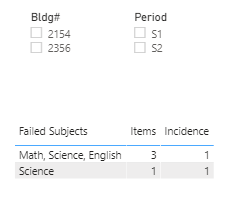
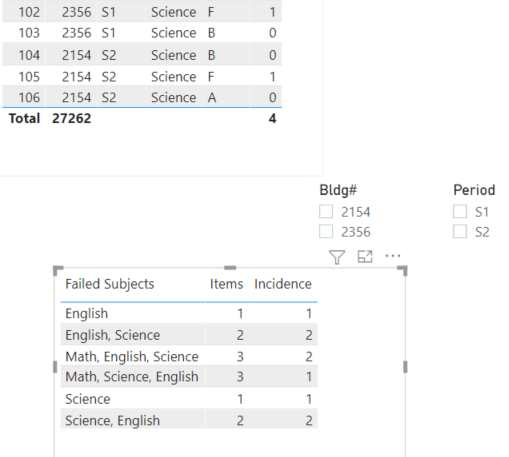
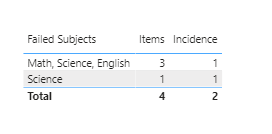
Thanks very much for the clarification, which made me realize this is much better done via Power Query than DAX. I produced the full results below, but if you only want to show rows with multiple items, you can add a final step in PQ to filter out any rows where Items = 1.
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WMjQwVNJRCgYRjkBsZGxqBqRc89JzMoszlGJ1QCqMYCpcECp8E0tg0sYwaSeEdHByZmpecipUhQkWFahWmMJUOGO1AmykEcyNhqYmGFaYwlQ4IVSgWmGCRQWqGcZYbMEREm64vIpNBRavGsFUoLkjFgA=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [ID = _t, Period = _t, Grade = _t, #"Bldg#" = _t, Subject = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"ID", Int64.Type}, {"Period", type text}, {"Grade", type text}, {"Bldg#", Int64.Type}, {"Subject", type text}}),
#"Sorted Rows" = Table.Sort(#"Changed Type",{{"ID", Order.Ascending}}),
#"Added Conditional Column" = Table.AddColumn(#"Sorted Rows", "Fail", each if [Grade] = "A" then 0 else if [Grade] = "D" then 1 else if [Grade] = "F" then 1 else if [Grade] = "B" then 0 else if [Grade] = "C" then 0 else null, type number),
#"Changed Type1" = Table.TransformColumnTypes(#"Added Conditional Column",{{"Fail", Int64.Type}}),
#"Filtered Rows" = Table.SelectRows(#"Changed Type1", each ([Fail] = 1)),
#"Removed Other Columns" = Table.SelectColumns(#"Filtered Rows",{"ID", "Subject"}),
#"Grouped Rows" = Table.Group(#"Removed Other Columns", {"ID"}, {{"All", each _, type table [ID=nullable number, Subject=nullable text]}, {"Count", each Table.RowCount(_), Int64.Type}}),
#"Added Custom" = Table.AddColumn(#"Grouped Rows", "Custom", each Table.SelectColumns( [All], "Subject" )),
#"Added Custom1" = Table.AddColumn(#"Added Custom", "Custom.1", each Table.ToList([Custom] )),
#"Extracted Values" = Table.TransformColumns(#"Added Custom1", {"Custom.1", each Text.Combine(List.Transform(_, Text.From), ", "), type text}),
#"Renamed Columns" = Table.RenameColumns(#"Extracted Values",{{"Custom.1", "Failed Subjects"}}),
#"Removed Other Columns1" = Table.SelectColumns(#"Renamed Columns",{"Count", "Failed Subjects"}),
#"Reordered Columns" = Table.ReorderColumns(#"Removed Other Columns1",{"Failed Subjects", "Count"}),
#"Renamed Columns1" = Table.RenameColumns(#"Reordered Columns",{{"Count", "Items"}}),
#"Grouped Rows1" = Table.Group(#"Renamed Columns1", {"Failed Subjects"}, {{"All", each _, type table [Failed Subjects=text, Items=number]}, {"Count", each Table.RowCount(_), Int64.Type}}),
#"Expanded All" = Table.ExpandTableColumn(#"Grouped Rows1", "All", {"Items"}, {"Items"}),
#"Renamed Columns2" = Table.RenameColumns(#"Expanded All",{{"Count", "Incidence"}}),
#"Changed Type2" = Table.TransformColumnTypes(#"Renamed Columns2",{{"Items", Int64.Type}})
in
#"Changed Type2"
I hope this hits the mark this time. Full revised solution file below.
– Brian
eDNA Forum - failing_courses solution.pbix (36.0 KB)