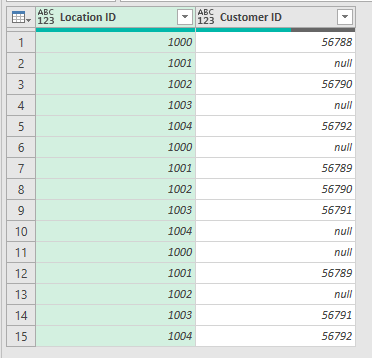
I have a five-column, 1.8M row fact table with two critical ID fields; Location ID and Custom ID. This is historical data - 2010-2018.
All Location IDs (18k Uniques) are present but some records are missing their Customer IDs in some years, not all years. Approximately 21k records in all.
I sorted the records by Location ID and Date ascending and I see that I want to “Fill-up” the records from later dates that do have the Customer IDs.
So, here’s my question: What M code approach can I take that lets me verify that both Location ID and Customer ID exist in the record and if so compare the Location ID field of the existing record to the Location ID of the previous record, and if it finds a match “Fills-up” the Customer ID into the blank field in the previous record?
Problem:
Rec# Location ID Customer ID
1 1000 -blank-
2 1000 56789
Solution:
Rec# Location ID Customer ID
1 1000 56789
2 1000 56789
Hi Randy, 1,8 Million sounds like a lot of lines, so merging might take time.
[If you do not want to work on the complete data set you could separate the 21k, work on the smaller dataset and then append the 21k back.]
Fill up would be risky as there might be records without any Customer ID at all. These would get the Customer ID of a different Record. So yes, merging seems to be an option. For safety reasons you can merge by Record and Location - that would obviously not be necessary/useful if REC# is a valid ID.
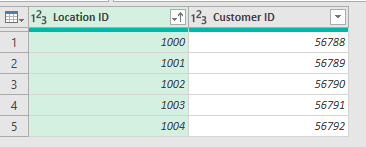
You do not want to create duplicates by merging, so you need to make sure that the dataset with Customer ID has only one row per entry.
One option could be:
merge the 21k w/o Customer ID with a copy of the complete data as right anti join so that only Records remain which are in some years blank. Get rid of the rows with blanks and then remove duplicates.
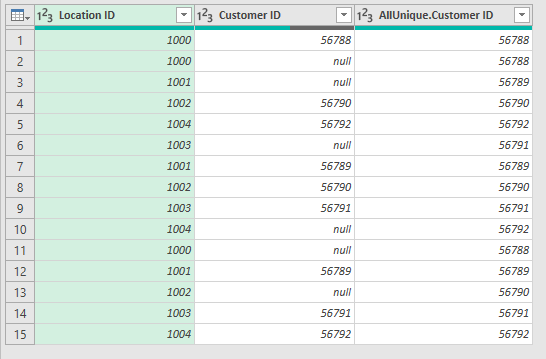
merge this set with Customer ID with the data set without. This time as left outer join. Expand.
you can replace the blank [Customer ID] with [Customer ID.1] like this:
Select [Customer ID] and make a right mouse selection of Replace Values . Press OK and then replace the text in the function bar to something similar like this:
= Table.ReplaceValue(prevStep, each if [Customer ID], each if [Customer ID]="" then [Customer ID.1] else [Customer ID], Replacer.ReplaceValue,{“Customer ID”})
Hope I understood the issue correctly and hope my description is clear enough.
Regards,
Matthias
PS: Wasn’t aware of jps’s response, and hope there are no contradictions.
Thank you, Japjeet. I tried the approach you suggested. Unfortunately, I started with 1.8M records pre-merge and created 2.07M+ records post-merge.
It may be because of the following data set detail I, unfortunately, left out of my problem description: Location IDs can have multiple Customer IDs associated with them. Out of the 18k unique Location IDs, 1886 of those have more than one Customer ID. No more than three or four at most, but it presented a problem while merging.
Thank you, Matthias. In my response to Japjeet, I relayed a critical piece of data I forgot to include in the original problem description: “Location IDs can have multiple Customer IDs associated with them.” Obviously, that matters while merging. I’m scratching my head over how to approach that aspect of merging record sets.
I will segregate the 21k records, work on them, then append – unless my revelation above changes the approach.
The data set does not have a record ID Key. I inherited this data set and I’m trying to determine the best fact/dimension approach for a solid data model.
In this case, It won’t be the best approach to merge based on LocationID & Customer ID.
Do you have a separate customer Table?
can you share sample data with all the columns?
As Matthias mentioned, Filling up or down the column can get you wrong results. You should be looking at what other tables you already have that we can use
REC# is useless, Location is shaky, sounds bad …
Not really, just put it into perspective, 18 million rows, just 21k open.
18k which you can solve and only 3k ambigious remaining.
And it is is all about historical data from 2018 and older, so it is not necessarily a big deal.
Here are some options you have:
-One (or both) of the other 2 columns could be used to decide which Customer ID to take: e.g. one Customer ID always goes with certain product(s) whereas the other Customer ID goes with other product(s). That might reduce the number of open cases.
-If can’t solve some multiples fill in all of them separated by a comma, so if someone needs to look for the details they at least know that there was an issue and have a choice (or choose the one which had more sales/transactions).
Thanks, Matthias, I had the same line of thinking – and you proved prescient. The updated reporting requirement I received today is for a rolling five years of historical data. I’m down to 84 rows after filtering non-relevant customer classes. I’ll hand-fill the source data file for those records. I think we’re done here! Thanks for your help!