Hi,
One of the interesting topics to me is the cohort analysis Showcase, I have some questions need your advice for one of my projects related to cohort analysis, My client has a data structure for (Sales orders, State Regions, Regions, Customer, and Products) around 90% Similar as cohort analysis showcase with some distinction in the following areas:
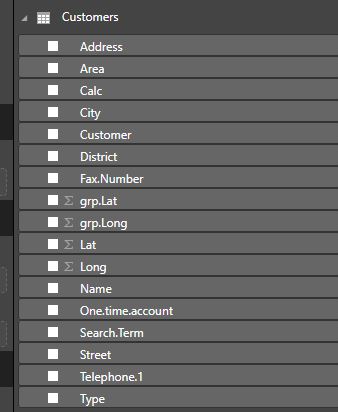
- The customer Table In addition to the Primary Unique Key have (Region No) as foreign key and Longitude and Latitude for customer address location as shown in the below screenshot:
-
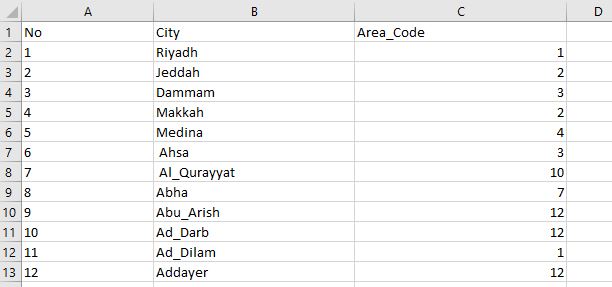
The Regions consists of Cities name with the Primary Unique Key and state No as shown in the below screenshot:
-
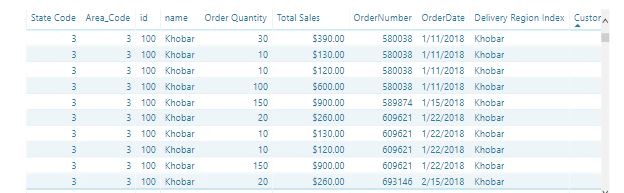
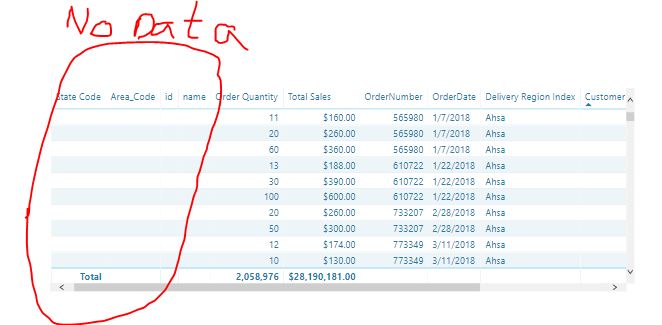
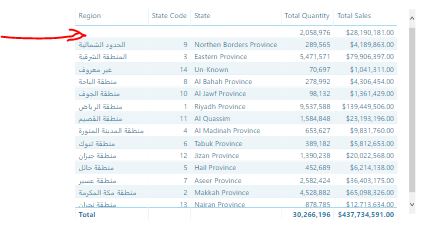
The Sales orders data have Composite Unique key for the Columns (Order No, Customer No, and Product No) as it is illustrated in the below screenshot:
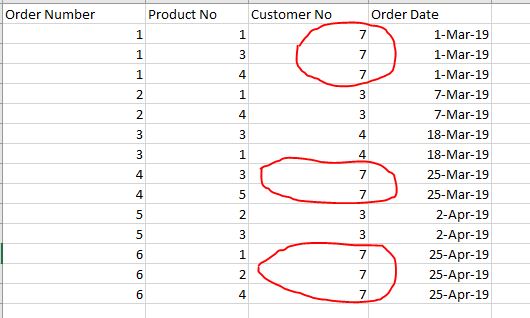
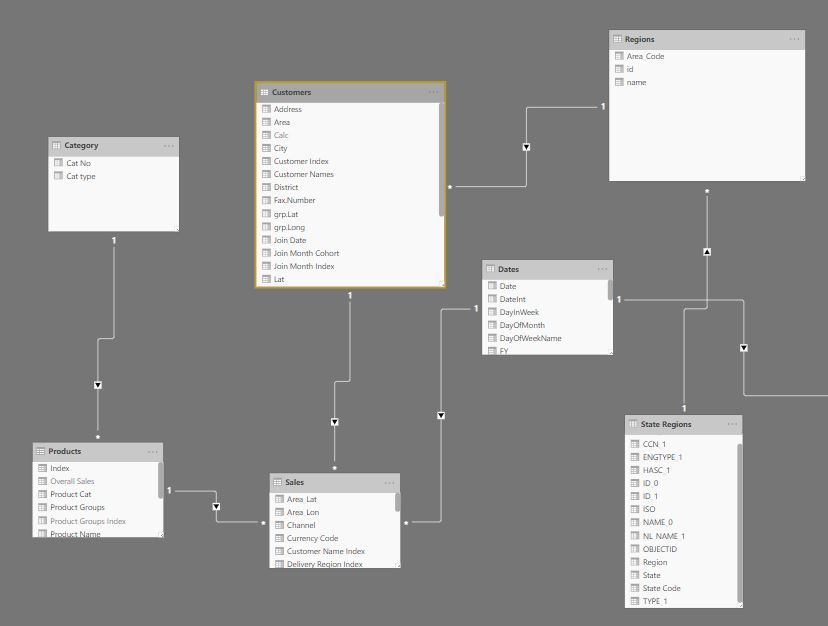
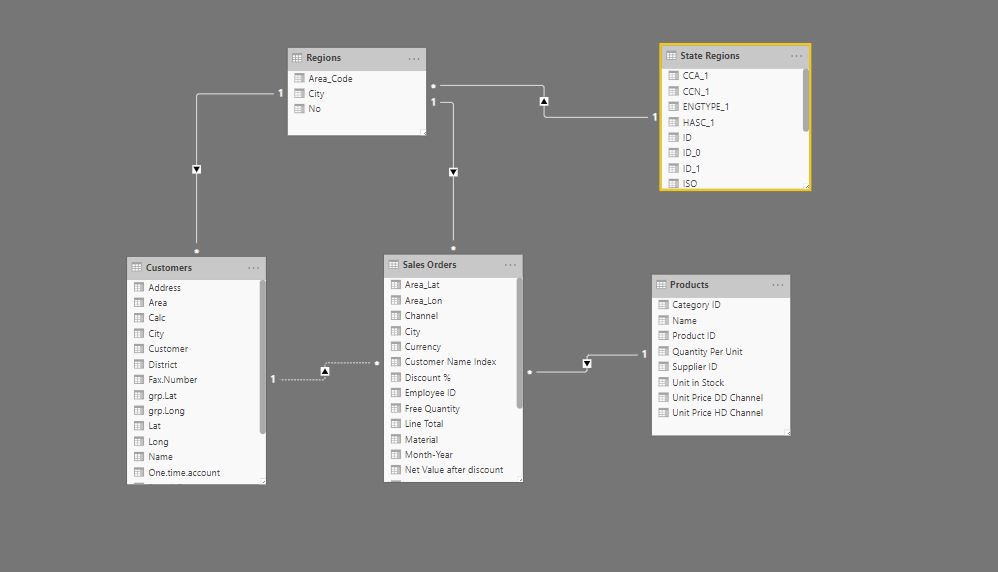
4)The primary relationship model diagram as shown in the following screenshot:
Aiming to gain advantages from your valuable resource showcase and to invest my time (not inventing the wheel) I’m trying to make my Data Model aligned with your showcase to minimize working efforts on my cohort analysis case, Based on the above introduction in sections (1-4) I have the following questions:
Q-1 Refer to Point (4) What is the more appropriate case to make (1: M) relationship on either one of these tables (City Or Customer) from one side and (Sales Order) in another side fitting with your (Measures) Modelling?
Q-2 The most important process in cohort analysis is counting the Customers frequency of purchasing On My Case In (3) for customer 7 details he purchased Products( 1,3,4) On 1st of March 2019, and on 25th March 2019 he purchased products (3,5), then he purchased (1,2,4) on 25th of March so if we calculate the total no of orders he purchase it would be 2 orders(times) in March and 1 time(order) in April, so his cohort details would be :
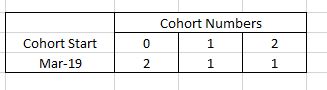
In the EDNA showcase, I found each order purchased with one customer like the case of customer
247 :
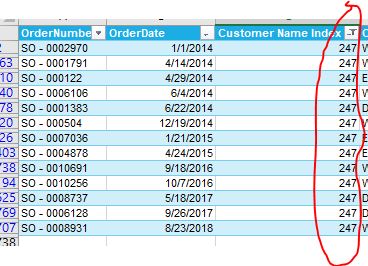
Is there a difference in the process of counting the purchases of the customer based on the design difference between sales order of my case and EDNA Showcase? if yes what sort of changes shall I do?