Hiya,
In my PBI model (Dual Mode), I have a couple of Dimensional tables (imported) connected to a single fact table (~700m rows via Direct Query) and they have one-to-many relationships and use a single cross filter. I am having some difficulties creating clustering measures or virtual table for Stores by their Sales due to the large volume of data in my fact table.
Below is the model:
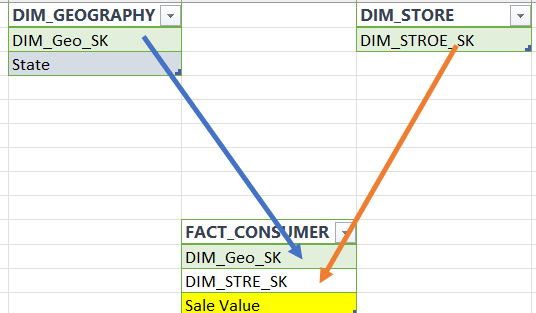
Goal:
I want to table or a virtual table that I can use without hitting the 1M rows error so I can cluster my Stores based on the Sales data. In PBI, my page has slicers from DIM_GEOGRAPHY (State and City).
The clustering option is "if FACT_CONSUMER[Sale Value] is between 0 to 33 then “poor”, 34 to 66 then “Good”, the rest would be “Top”.
Greatly appreciate any help.