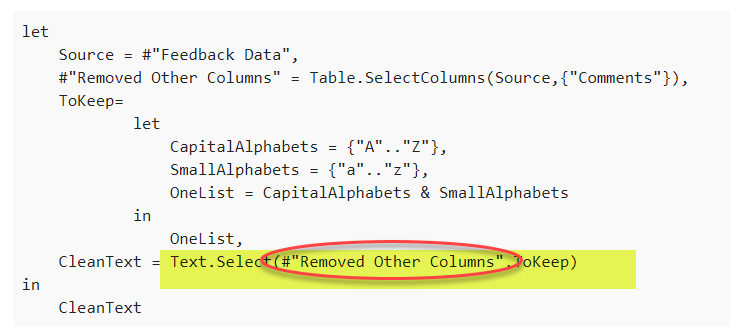
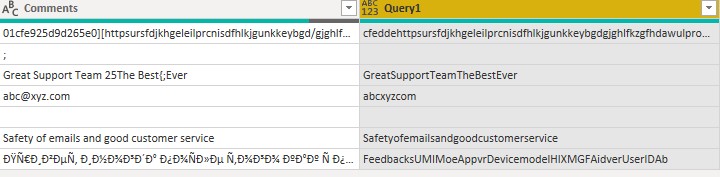
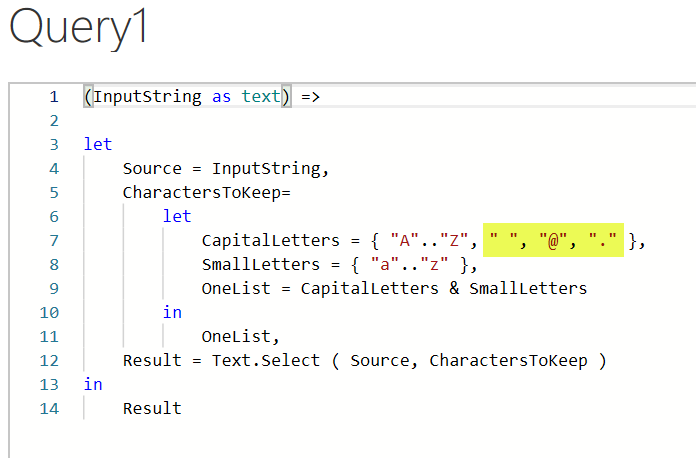
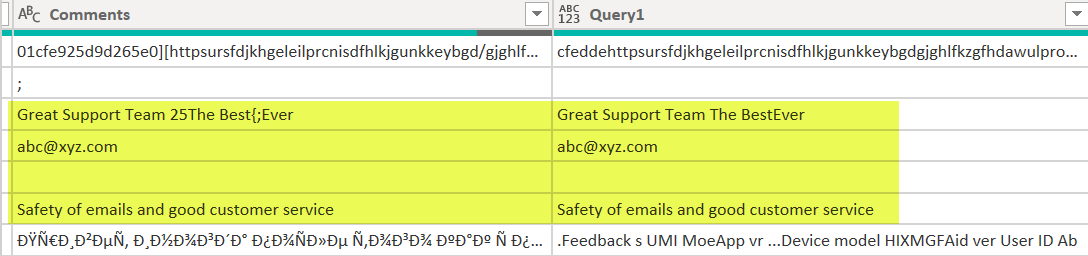
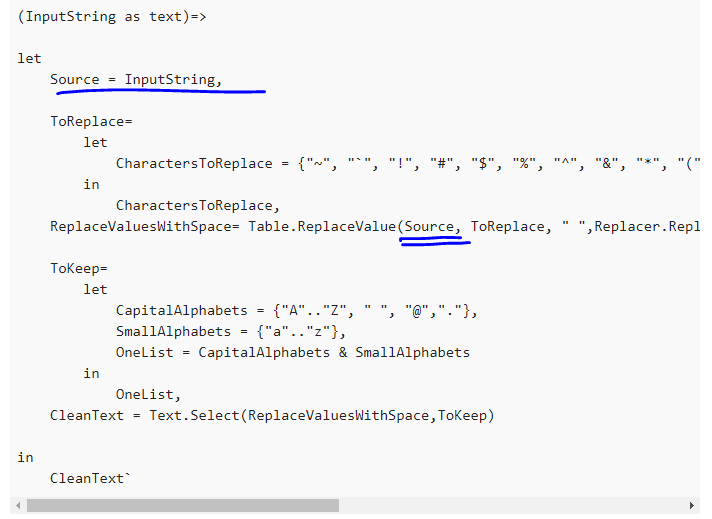
Hello,
I have a comments column in my dataset on which I need to apply text analytics. Now I am dealing with lot of messy text, some of which I am unable to clean through User Interface in power Query here are some examples :
-
there are several long urls that have different lengths varying from 40 to 500 characters
-
Comments like : #8d9fc1ca-b858-4af6-8d4a-d4980ad46954-session-1629408347593_8de43ac12d564e449409aecb4bed2815Thanks
-
bff1bf79-9221-4df6-bcdb-9597f1ce6bf2desk:
4){color:white;font-size:14px;margin:4px 0;font-weight:bold;}#TOU5256405
-
прочитано.
-
SentencesWithNoSpaceBetweenWords - It would be interesting to know if there is a way to get this type of text in separate meaningful words
What will be the best approach to handle/ rather clean such data, I am looking to create a word cloud and use the Cognitive services for sentiment analysis.