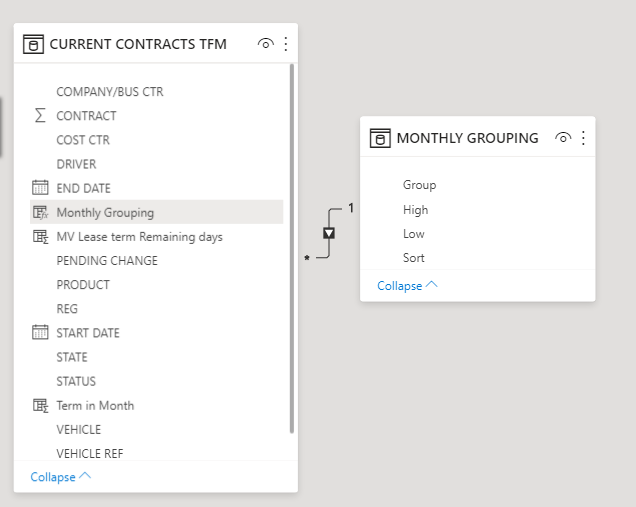
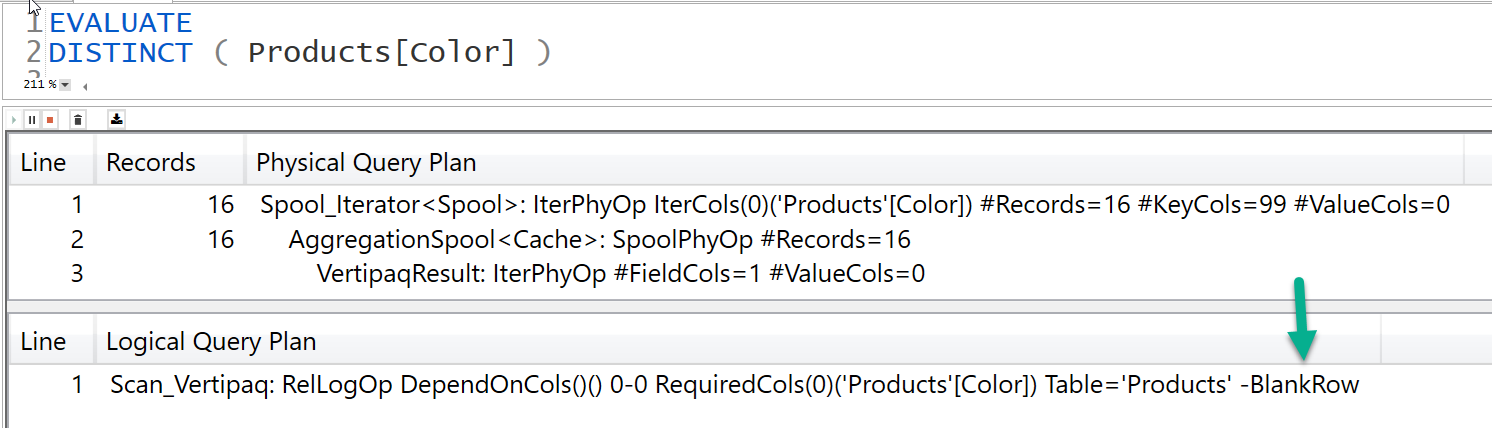
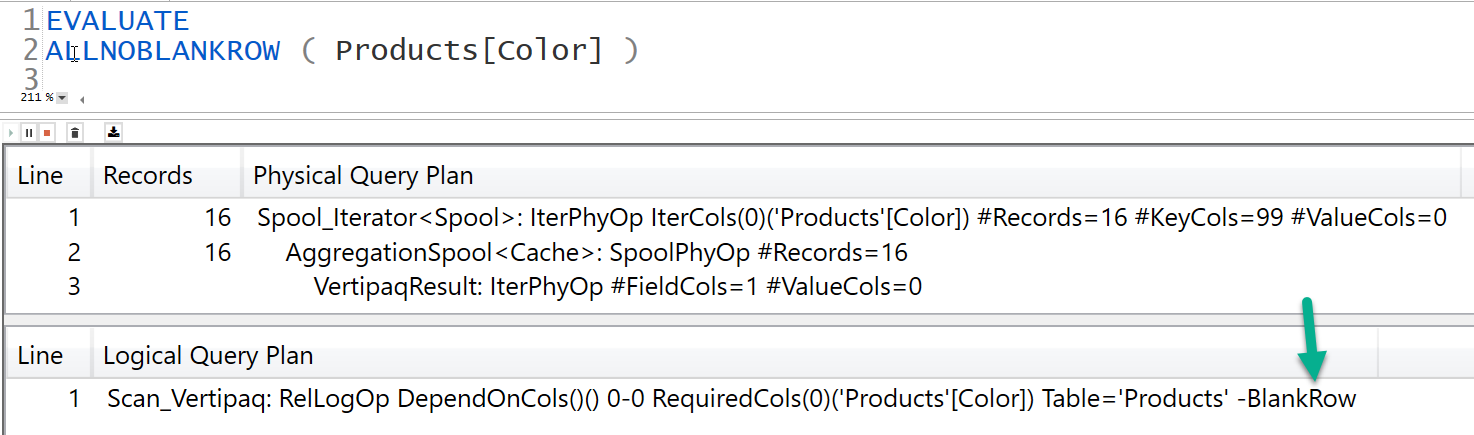
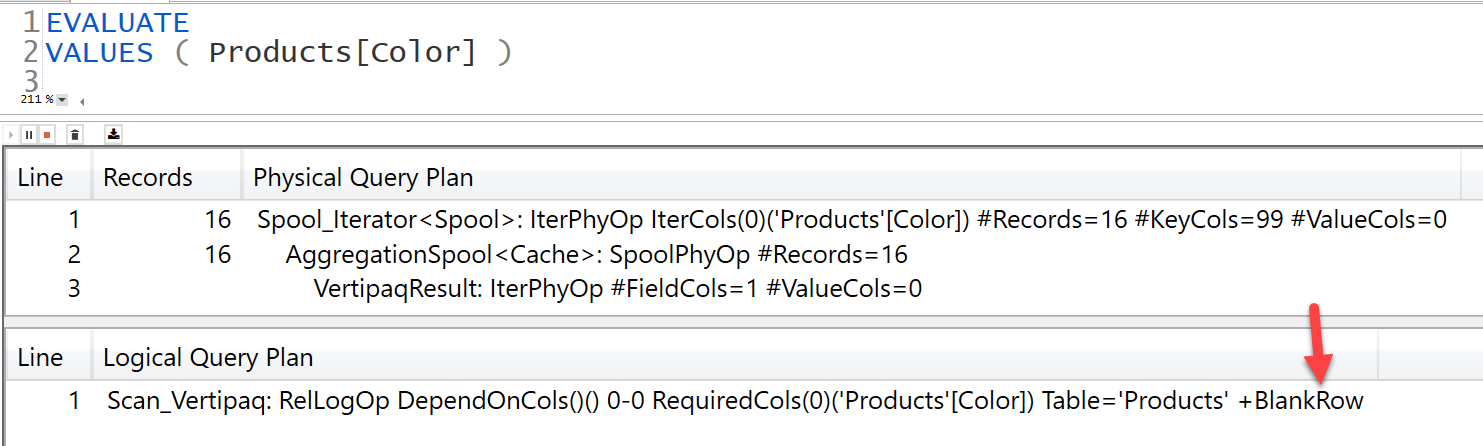
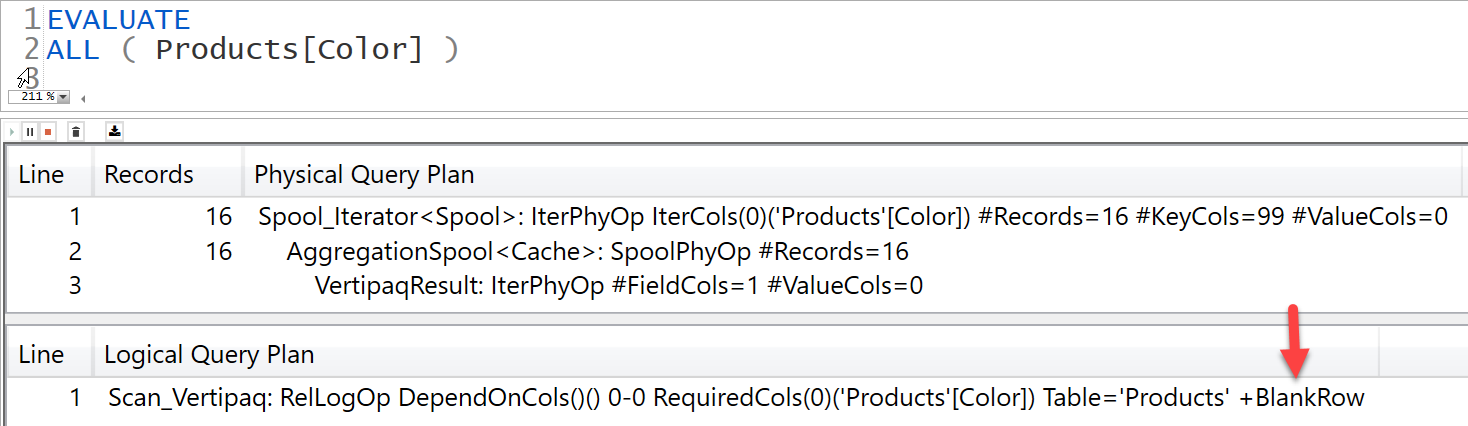
That’s because VALUES considers the blank row added by the engine to the one side of the relationship in case of an invalid relationship, this is not to say that your model has a flaw in any way but it is a proactive approach to ensure in case there are invalid relationship in your model meaning Fact table has items that do not belong to the Dimension table then those items will be grouped under a blank row added to Dimension table.
Now when you try to create the relationship the following happens:
Dimension table depends on Fact table for the blank row because of invalid relationship (even though it may not happen at the moment in your case but it can happen in the future, that’s why it is designed keeping that in mind )
Fact table depends on Dimension table for the blank row because of the use of VALUES
That’s why there is a circular dependency.
Another solution is to use DISTINCT/ALLNOBLANKROW instead of VALUES/ALL
Okay, potentially dumb question here but given that the categories in the helper table are mutually exclusive and thus will always return a single value for any value of Term in Month, why not just simplify matters and use a basic aggregator like MIN or MAX as the first term in the calculate function. This avoids the circular reference and also would likely perform faster, since that calculation would be done in the storage engine. What am I missing here?
@BrianJ No differences, as you have said there will always be single value in the case, so really doesn’t matter what you use.
Regarding calculation in Vertipaq, it won’t happen since MAX is being executed on a text field, if you do MAX on MONTHLY GROUPING’[Sort] then it will be done in SE. But the difference is not even visible.