Hi there
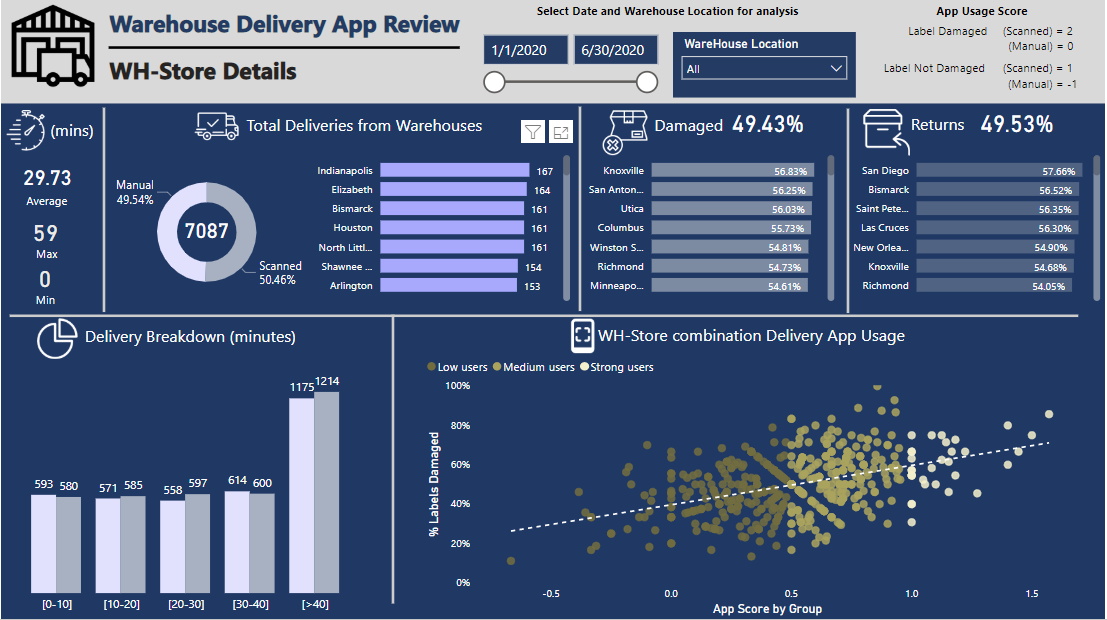
The problem statement for the challenge was focused on the usage of Delivery App developed by the consultancy firm and my analysis was mainly focused to develop some kind of a metric around that for each WH-store combination.
In order to see which WH-store combination is using the App regularly, I have created a metric called ‘App usage score’ and the average value of each WH-store combination is calculated, based on the number of deliveries.
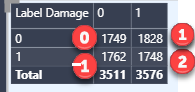
The scoring system for ‘App usage score’ for each delivery I have used is
Label Damaged (Scanned) = 2
Label Damaged (Manual) = 0
Label Not Damaged (Scanned) = 1
Label Not Damaged (Manual) = -1
The scoring system benefits the app users (those who scan) with an extra point for scanning even when the label is damaged, and penalizes (with -1) all those who do not scan, even when the Label is perfectly OK.
The average app score for all WH-Store combination is then used to segment the WH-store combination in User Groups (Strong, medium and low). I have used a scatter plot to compare the average app score with % Labels damaged. Other parameters like Parcels damaged, Returns collected and Time spent can also be used for comparison. The reason behind using Labels Damaged was to highlight WH-store combinations trying their best to use the app, even with labels being damaged, and vice versa. The management can then work with these combinations for follow up action in the next phase of app development.
The other key measures are avg, min and max time spent for each WH-store combination inside the store, the total number of deliveries and how the delivery can be broken down into Timing Groups for each WH-store combination, parcels damaged and returns collected for all WH-Store combinations.
I have used 5 categories, [0-10], [10-20], [20-30], [30-40] and [>40] for Timing Group based segmentation and all deliveries are further divided into Manual/Scanned
I have tried to limit myself to a dashboard instead of a detailed report to avoid an analysis-paralysis situation, as I feel that ‘Delivery App usage’ was the main parameter and rest of the measures can be easily seen in context with app usage on the dashboard.
Color scheme and layout is inspired by the pattern of most designs showcased by @sam.mckay on the portal.
Looking for feedback / suggestion on the submission so I can improve in future.
Thanks
Abu Bakar Alvi