Let me start by saying I’ve read several - possibly not all - questions posted about the subject that the forum conveniently offered when writing this.
I find most answers possibly correct, but unsatisfactory as in opening more questions. Things like “experts recommend using star or snowflake schema” and "the issue is not of bad existing connections, but more in connections missing [to cut down processing power when cross-matching two fact tables).
So here’s the situation:
I am doing a project with the public MovieLens database.
My version looks like this:
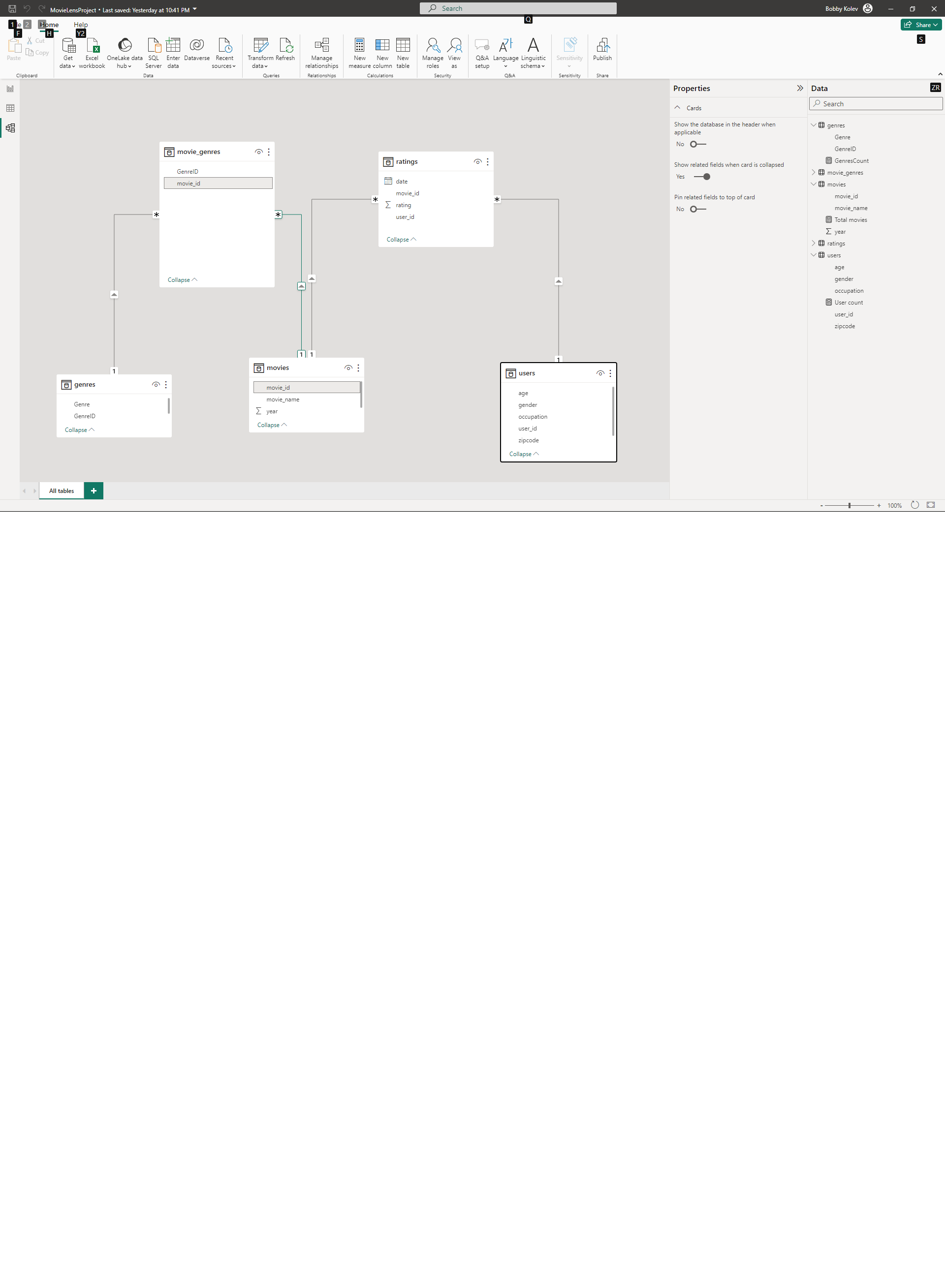
There is the Movies table containing all unique movies with their unique IDs.
Each movie can be classified in one or more different genres, so there is a Genres table for the unique genders and MovieGenres table that contains one or more pairs of movie and genre.
(the Genres and MovieGenres can indeed be flattened and for the sake of speed and performance maybe should (at the cost of size), but that’s not the problem so let them be).
Each movie can also have multiple ratings coming from various users, hence the Ratings and Users tables.
The format is fairly simple for a database design, but PowerBI is choking on it every time when the two large tables (in the design they also look like fact tables due to their outgoing *:1 relationships) and a third table, which is not the one between them, is used.
The offered explanations vary from “you run into problems whenever you do not use a star or snowflake” to “it’s because PowerBI data engine can’t find a way to decrease very computing expensive corss-select operation” (though that’s not what the message is saying).
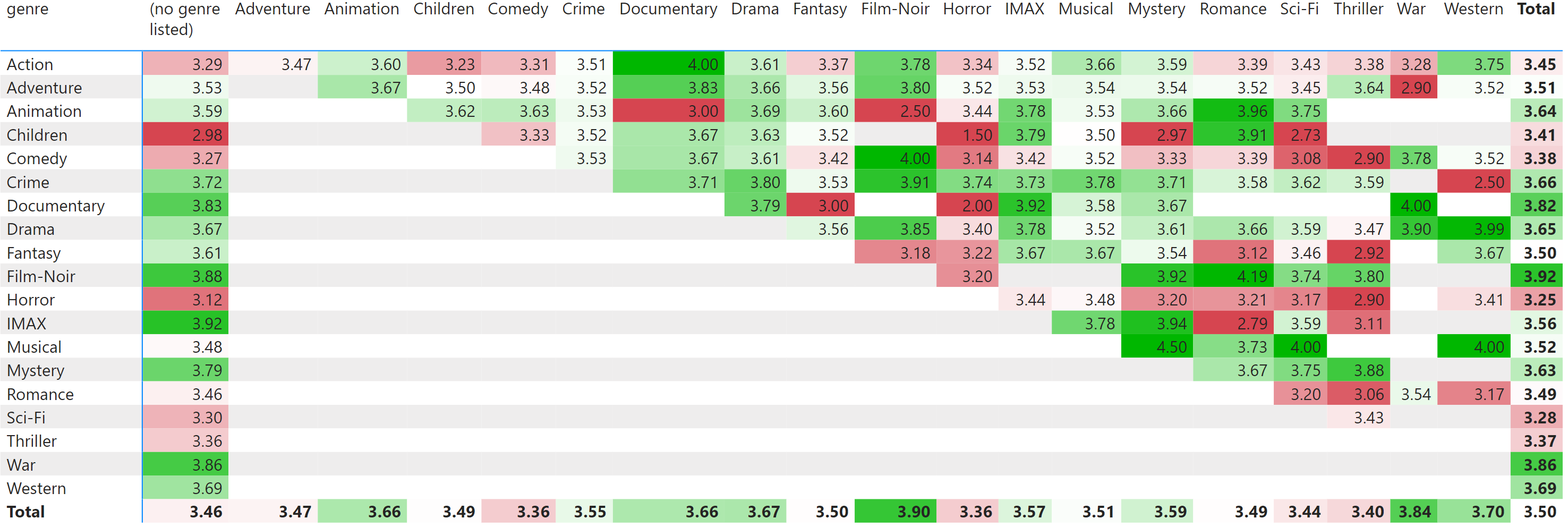
My very first question is what would be the correct design that allows answering the question “what are the highest rated combinations of 1, 2 and 3 genres in a movie?”, which I think is a fairly good thing to ask. If Adventure|Sci-Fi is liked more than Adventure:Travel then that’s where the money goes…
Both apparent possibilities - adding more columns into the “Movies” table - ether N columns for up to N genres (hardcoded limit) or <number_of_genres> columns with binary yes/no for each genre - come at a great subsequent complication in subsequent processing if the genres and combinations thereof are to be considered equal.
My second question is…what really is the limit imposed by the engine?
I am curious as it would help me understand how it works and what can I expect from it.
Like this I expected would be something fairly trivial. At worst I thought it may hang in processing for a while. But neither the size nor the task itself are a challenge for any modern SQL server, so the only thing I wasn’t expecting was rejection.
I don’t think those at Microsoft are so bad they’d cut a feature just because it may take some extra time; ultimately that is client’s call and it also depends on processing power and database size, so it’s hard to imagine they’ve just blocked it for everyone.
It is more likely to assume they are indeed facing a technical problem that can’t be solved, which means PowerBI is doing something that I do not understand.
So I want to understand it. Otherwise the combination of me and PowerBI is not very different from that of a Porche driven by a smart monkey ![]()
Hope it makes sense.
Thank you for reading this all.