Hi everyone.
I’m working my way through the different courses and try to optimize the report I’m creating along the way. The report will essentially be for the entire company so I want to implement as many best practices as I can along the way. So far, the report has data about all orders (blue) as well as invoiced sales (green).
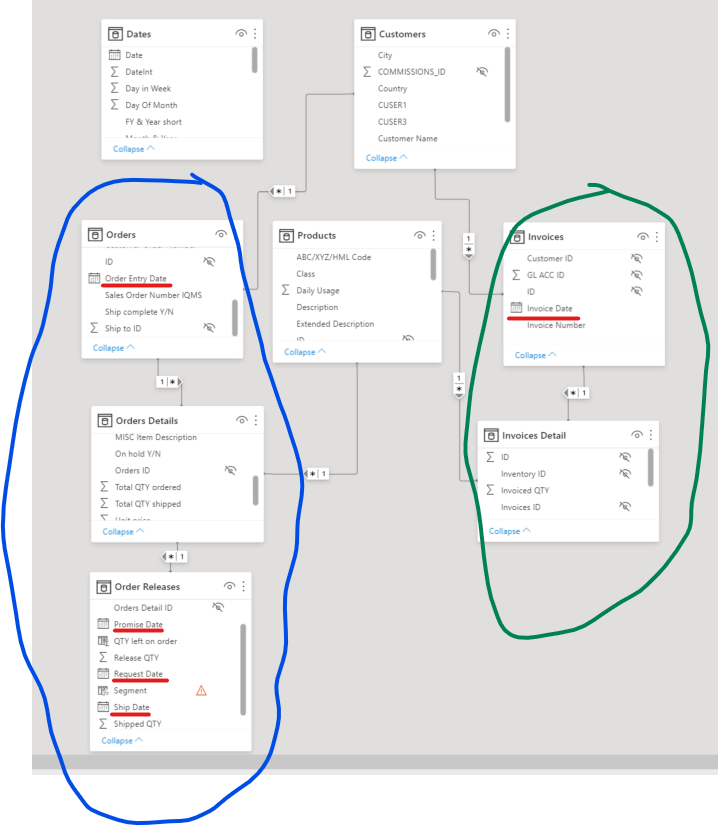
As you can see, the tables in our system have some kind of hierarchy. There is usually some kind of header table holding the general information and then there is a detailed table holding the details on an line item level. For the backlog, there is an additional table that holds the information about each release for the data on the item level. For the invoiced sales, it is only two levels but still the same thing. In addition, important dates for my time intelligence are spread over multiple tables. (Date relations not setup yet)
What I learned so far regarding best practices for the data model, this is not a best practice model. If necessary, I would like to have clear fact and lookup tables.
My main questions are:
-
Is there a video in the courses regarding this issue? I am somewhat overwhelmed by the amount of videos there are and I’m not clear where to look for a solution.
-
What is the best way to consolidate? I could think of merging queries, but merging the queries makes updates and changes to the data source very slow and is kind of a pain if I want to scale up.
It would be great if I can get pointed into the right direction how to get there.
Thank you very much.
Nico