@Rafal_J,
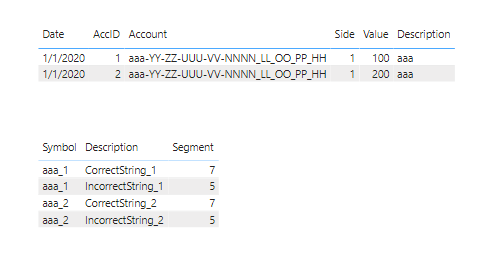
See how this solution works for you. Below is the final table I created with all the account dimension information in it. I provide two different ways to create a unique Account Key. The first is a simple approach that concatenates Account Key with segment number to create a unique ID.
The second is a trick I really like that uses an invisible nonprinting character to create a unique ID. You can see that even though looking at the column Account Key Unique 2, there appear to be duplicates, when you look at the length column you’ll notice that each pair of apparent duplicates has a different length, and thus Power BI views them as unique. If you use this approach, you’ll need to apply it to your fact table as well in order that you can match the appropriate record in the dimension table to the correct record(s) in the fact table.
For the Description field, I used a basic if/then/else M code structure based on the value of Segment.
Here’s the full M code:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WMtQ31DcyMDJQ0lEyBOLExETdyEjdqCjd0NBQ3bAwXT8giPfxiff3jw8IiPfwAKkzQFKtFKuDYogRkYYYoRoSCwA=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Date = _t, AccID = _t, Account = _t, Value = _t, Side = _t, Description = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Date", type date}, {"AccID", Int64.Type}, {"Account", type text}, {"Value", Int64.Type}, {"Side", Int64.Type}, {"Description", type text}}),
#"Added Custom" = Table.AddColumn(#"Changed Type", "Acct Key", each Text.Start( [Account], 3 ) &"_"& Text.From( [AccID] )),
#"Removed Columns" = Table.RemoveColumns(#"Added Custom",{"Description"}),
#"Merged Queries" = Table.NestedJoin(#"Removed Columns", {"Acct Key"}, #"Table 2", {"Symbol"}, "Table 2", JoinKind.LeftOuter),
#"Expanded Table 2" = Table.ExpandTableColumn(#"Merged Queries", "Table 2", {"Segment"}, {"Segment"}),
#"Added Custom1" = Table.AddColumn(#"Expanded Table 2", "Description", each if [Segment] = 7 then "CorrectString" else "IncorrectString"),
#"Added Custom2" = Table.AddColumn(#"Added Custom1", "Acct Key Unique1", each [Acct Key] &"_"& Text.From( [Segment] )),
#"Grouped Rows" = Table.Group(#"Added Custom2", {"Acct Key"}, {{"Data", each _, type table [Date=nullable date, AccID=nullable number, Account=nullable text, Value=nullable number, Side=nullable number, Acct Key=text, Segment=nullable number, Description=text, Acct Key Unique1=text]}}),
#"Added Custom3" = Table.AddColumn(#"Grouped Rows", "Custom", each Table.AddIndexColumn([Data], "Index", 1, 1)),
#"Removed Other Columns" = Table.SelectColumns(#"Added Custom3",{"Custom"}),
#"Expanded Custom" = Table.ExpandTableColumn(#"Removed Other Columns", "Custom", {"Date", "AccID", "Account", "Value", "Side", "Acct Key", "Segment", "Description", "Acct Key Unique1", "Index"}, {"Date", "AccID", "Account", "Value", "Side", "Acct Key", "Segment", "Description", "Acct Key Unique1", "Index"}),
#"Added Custom4" = Table.AddColumn(#"Expanded Custom", "Acct Key Unique 2", each [Acct Key] & Text.Repeat( Character.FromNumber( 8204 ), [Index] - 1)),
#"Changed Type1" = Table.TransformColumnTypes(#"Added Custom4",{{"Index", Int64.Type}}),
#"Duplicated Column" = Table.DuplicateColumn(#"Changed Type1", "Acct Key Unique 2", "Acct Key Unique 2 - Copy"),
#"Calculated Text Length" = Table.TransformColumns(#"Duplicated Column",{{"Acct Key Unique 2 - Copy", Text.Length, Int64.Type}}),
#"Renamed Columns" = Table.RenameColumns(#"Calculated Text Length",{{"Acct Key Unique 2 - Copy", "Acct Key Unique 2 - Length"}})
in
#"Renamed Columns"
I hope this gets you what you need. Feel free to give me a shout if you have any questions. Full solution file attached below.