I have a very simple sample data, two tables one for amounts and the other for %.
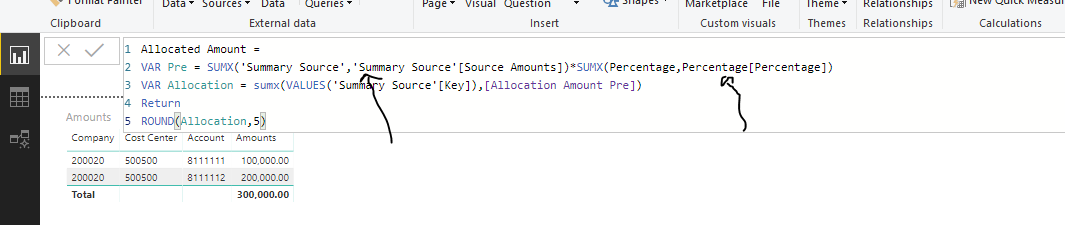
I created a key field to link both together. The allocation simply takes the source amounts with credit value and charge it to different coding as per the data in the percentage table.
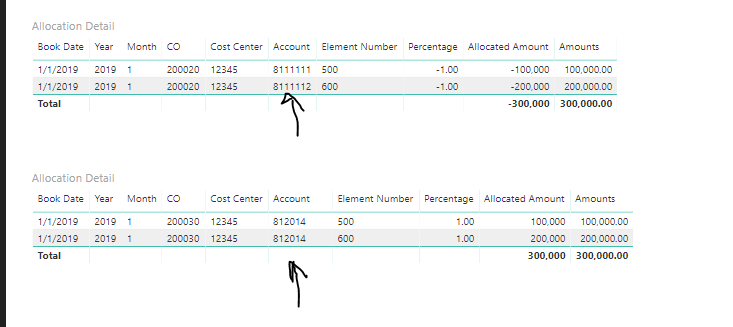
I can achieve the results in doing two visuals as per below, but I want to be able to create a table that contains all data for the credits and the debits.
I created two visuals since the credit amounts have to clear the original records and the debits amounts have to follow the percentage table.
The key here is to get all the relevant dimension into your lookup table/s. This way they can filter all of your calculation naturally by the relationships you have.
Is ‘key’ the only common dimension?
To me with the additional context you have in your table the formulas aren’t working as you expect here.
Only use SUMX when you actually need to work some logic at every single rows into the calculation. A simple SUM here should work fine from my perspective.
I think you need to improve the model here to get this right. I’m not sure exactly of the solution, but that’s the problem here.
It’s also to me not clear how the allocation is meant to be done. What is the true logic behind this allocation?
Thank you Sam, The first visual is the visual that clears the cost to zero. The percentage is -1 so we need the accounts to be the same as the source table 811111 and 811112.
The second visual is to charge the amounts to the destination accounts so the accounts in this visual come from the percentage table.
The logic behind the allocation is to allocate the amounts to different companies and accounts, as per the second visual accounts are different and companies are different.
I will adjust the sumx as you mentioned, I started PowerBi only couple of months ago so there are still confusing concepts to me.