Check out this solution here, it’s almost identical to what you require.
The key is to create a secondary table and iterate through it.
It is actually exactly the same. You can just copy it completely.
Here’s something I quickly wiped up
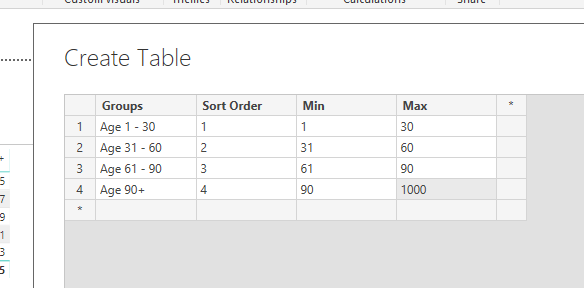
Cost Per Group =
CALCULATE( [Total Value],
FILTER( 'Transaction Table',
COUNTROWS(
FILTER( 'Aged Debtors Group',
DATEDIFF('Transaction Table'[Due Date], 'Transaction Table'[Clearing Date], DAY) >= 'Aged Debtors Group'[Min] &&
DATEDIFF('Transaction Table'[Due Date],'Transaction Table'[Clearing Date], DAY) <= 'Aged Debtors Group'[Max] ) ) > 0 ) )
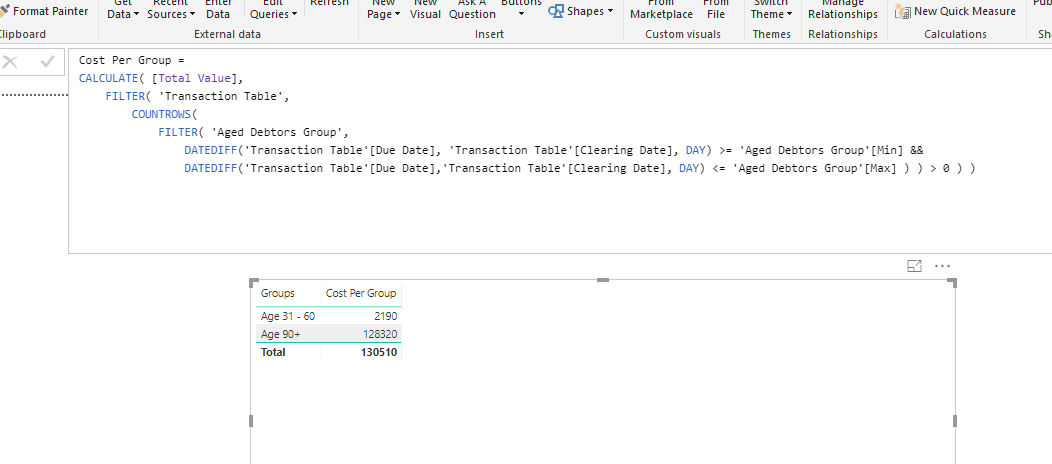
Let me know if this is what you were targeting. Maybe you might have to have a play around with the concept to get it exactly right.
Attached
Aged Trial Balance Example Data.pbix (125.4 KB)