I inherited a massive data model, which was created by a data consultancy firm no longer working with my client.
Basically, the consultancy firm brought every data table relevant to the business (from a CRM, appointment manager, call center software, financial software, etc.). This includes 10 or so fact tables ( each with 100,000+ rows), along with over a dozen dimension tables (including 6+ date tables to filter all the fact tables). Here’s a screenshot of the data model that I inherited:
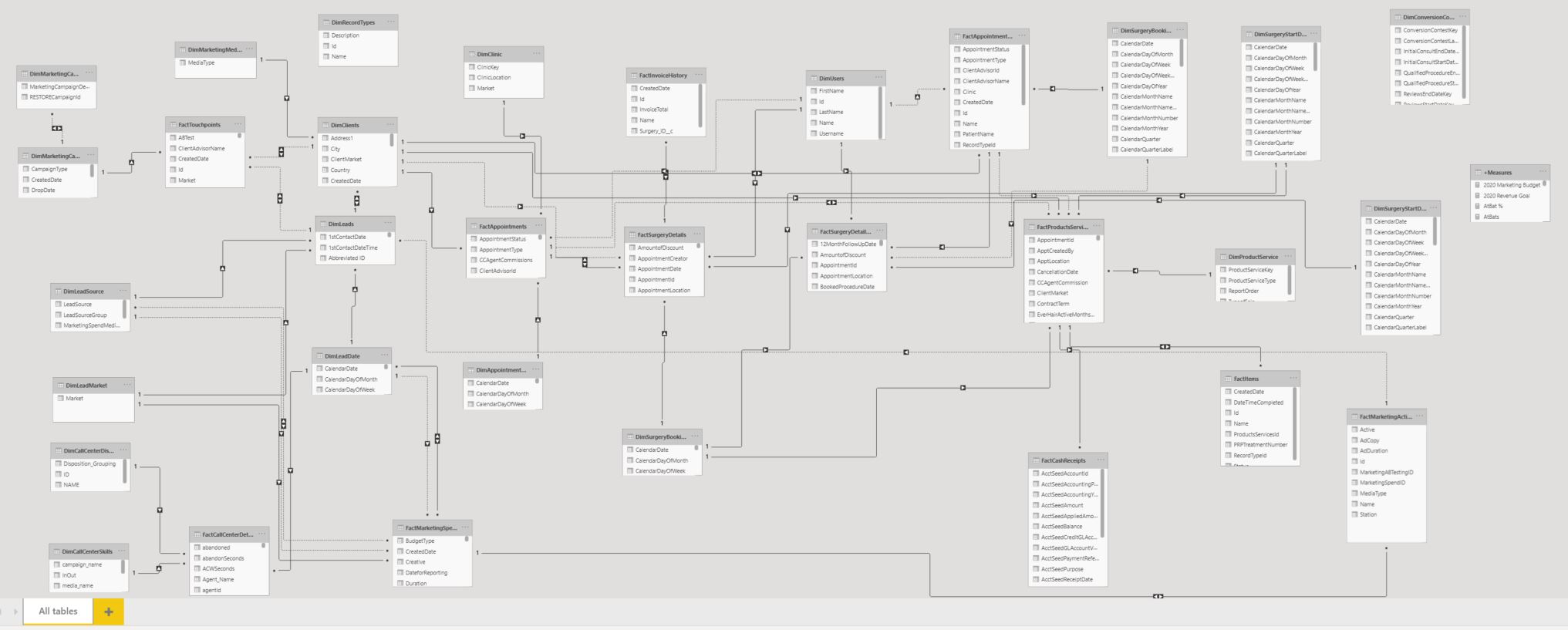
This same consultancy firm went on to create numerous dashboards in Power BI, setting up a hundred or so relationships between the tables, some active, many inactive due to circular redundancy.
Each dashboard on its own uses only a fraction of the tables stored in the model. For example, there is a sales dashboard, which uses the fact tables and dimension tables related to sales (while ignoring all the other tables that contain call center data, appointment data, or marketing data, for example). There is also a call center dashboard, which uses only the tables related to the call center, while ignoring the other tables.
This means that there is a huge amount of data sitting unused in the data model when looking at each individual dashboard. Whiel each dashboard references 6-7 tables, the remaining 20 tables are sitting in the model unused.
Due to the sheer size of all this data stored in these tables, Power BI is agonizingly slow. It takes 30 seconds, for example, to change the file location of a measure from a fact table to my measures folder. Another 30 seconds to click “create measure”, and another 30 seconds when you click “enter” to actually create the measure.
I’m wondering what are the best practices here? It seems to me to make more sense to upload ONLY the tables that are relevant to the dashboard/visualizations being built, and to delete the rest from the model so they don’t slow everything else down.
What would be the benefit of keeping all the data tables available all the time, even if they aren’t being used by a particular report?
Thanks,
Pete