EDNA 5 Bel - snapshot.pptx (187.7 KB)
SalesOrders 8-16 pre-history fix eg five below fob.docx (14.0 KB)
*** READ FIRST ***
Dear Forum:
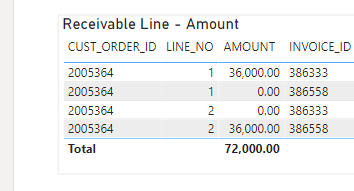
I have an issue with a native query I used to pull together three SQL tables in Power Query. What is occurring is I am getting duplicate values. I am seeking help to rewrite the SQL query which I have attached. My example is for Order 2005364 / Part ID = DP 7451.
I have tried deleting duplicate rows using different scenarios but image my Native SQL statement is where it should be corrected.
I have tried to upload the pbix but am having trouble due to file size but am attaching the data file. It also requires special credentials I am not able to share. I have attached both a word document with the code underlined and highlighted where I think the problem is as well a screenshot showing the results for this example. I’m not sure how to apply composite keys in my native query and do not have access to the dbase for changing it.
Any help on this query is greatly appreciated.
Thank you very much!
P.S. I can send data file if needed but it won’t upload due to size…
- Your current work-in-progress PBIX file - VERY IMPORTANT
- A clear explanation of the problem you are experiencing
- A mockup of the results you want to achieve
- Your underlying data file
Check out this thread on Tools and Techniques for Providing PBIX Files with Your Forum Questions
Also make sure that your data file contains no confidential information. If it does, click the link above.
*** DELETE THIS MESSAGE IF YOU ARE SURE ALL YOUR DETAILS ARE COMPLETE OR IF THE ABOVE INFORMATION IS NOT APPLICABLE TO YOUR QUESTION.***