Estimated difficulty level:
INTRO
In this workout, the second in our series of dealing with many-to-many relationships, we are going to focus on a technique that has been an absolute game-changer for me in elevating my data modeling skills - adjusting mismatched granularities.
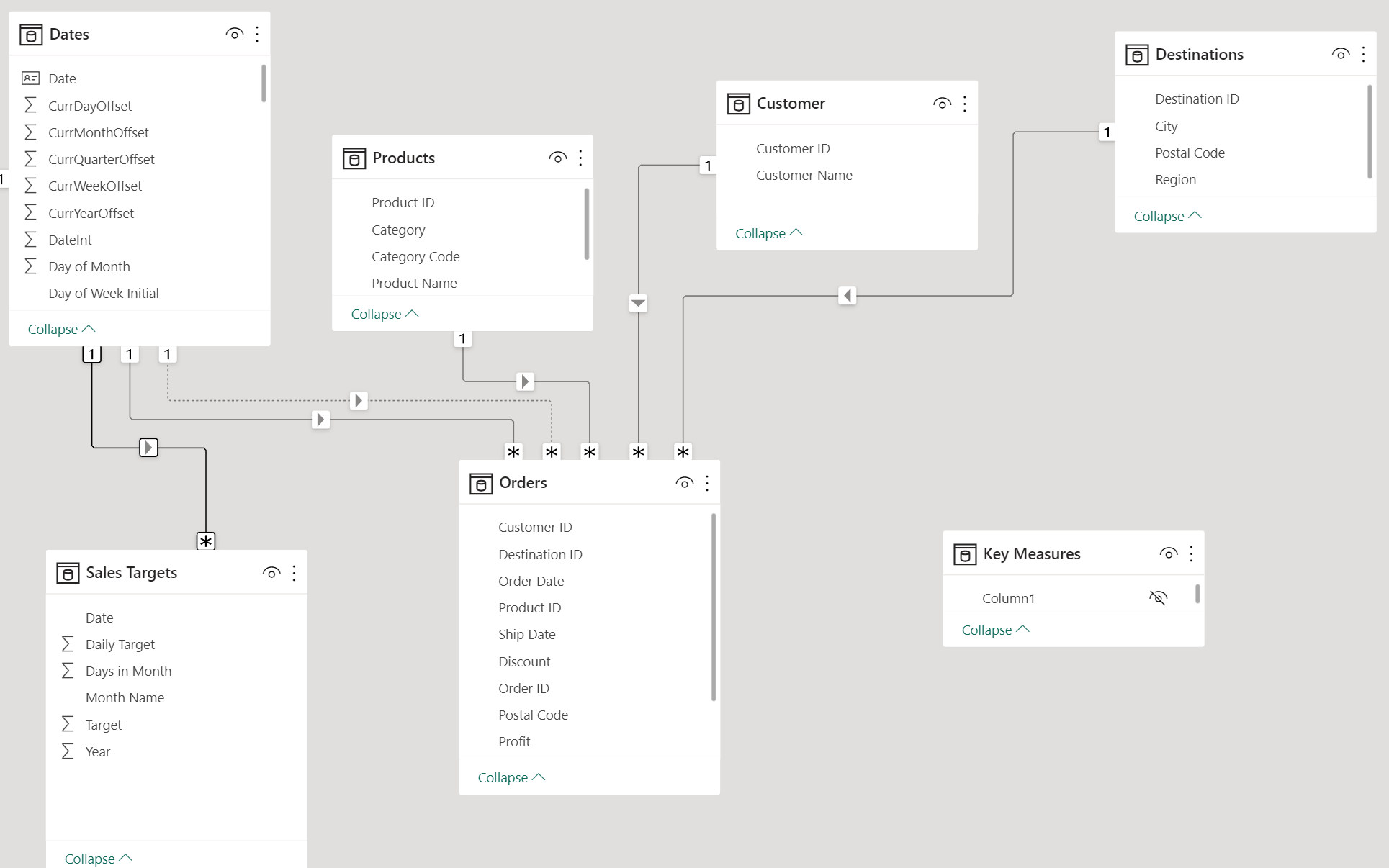
In this week’s workout, our many-to-many dilemma results from a mismatched granularity between our Dates table (daily granularity) and our Monthly Sales Targets (obviously, monthly granularity).
However, by allocating the monthly targets to daily granularity, the many-to-many problem disappears, and we can simply connect the Dates table to the Sales Targets table in a 1:M relationship, maintaining our nice star schema model.
This scenario comes up quite frequently, and mastering the technique here will give you a flexible and powerful weapon in your data modeling arsenal.
So, let’s get to it!..
OBJECTIVES:
For this Workout, we return to the office supply store we addressed in Workout 003.
In that Workout, we denormalized a snowflake schema into the standard star schema we now have here.
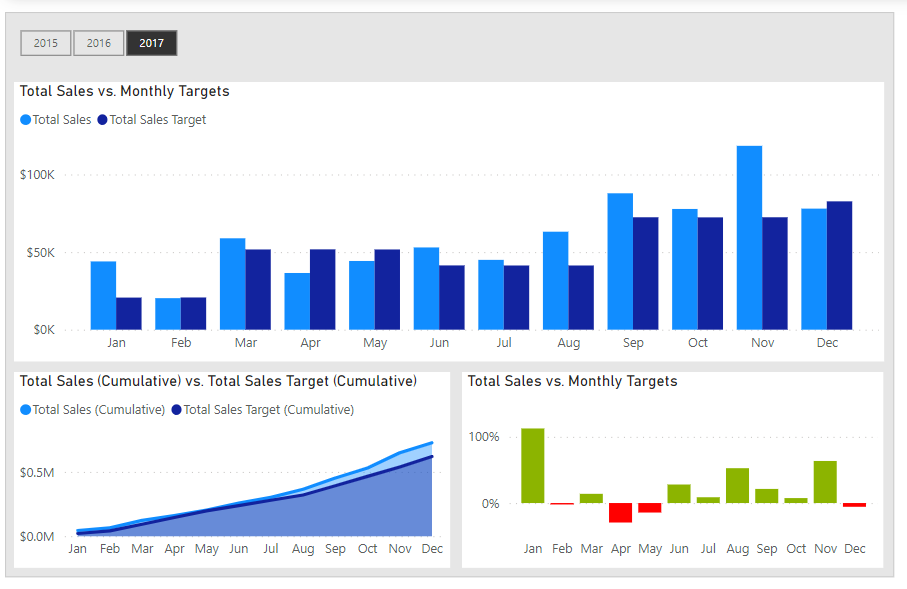
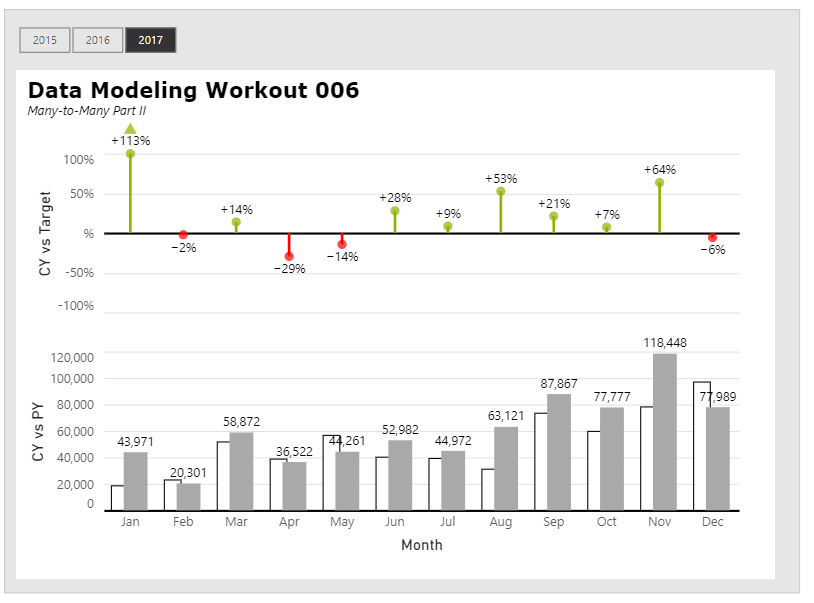
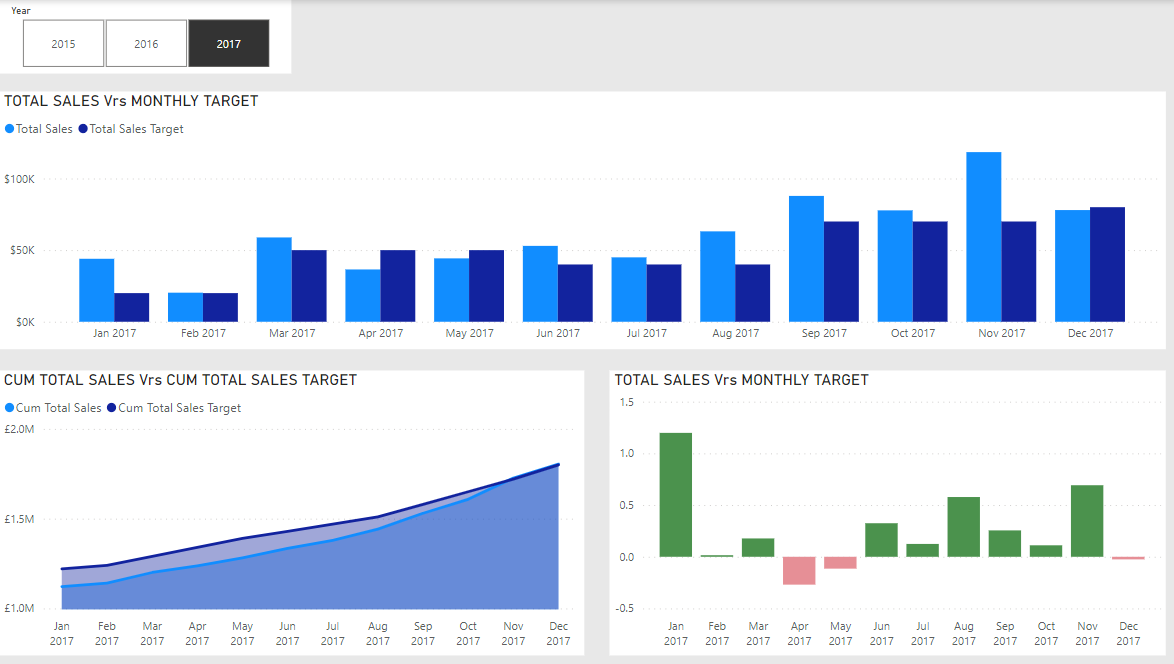
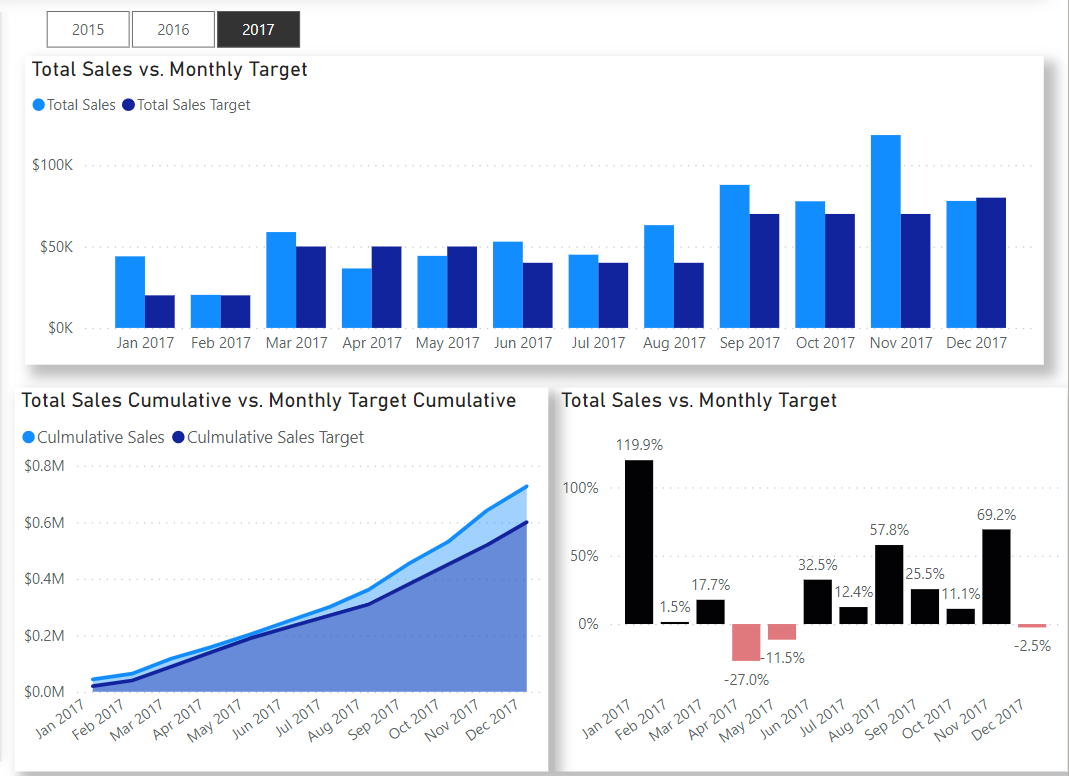
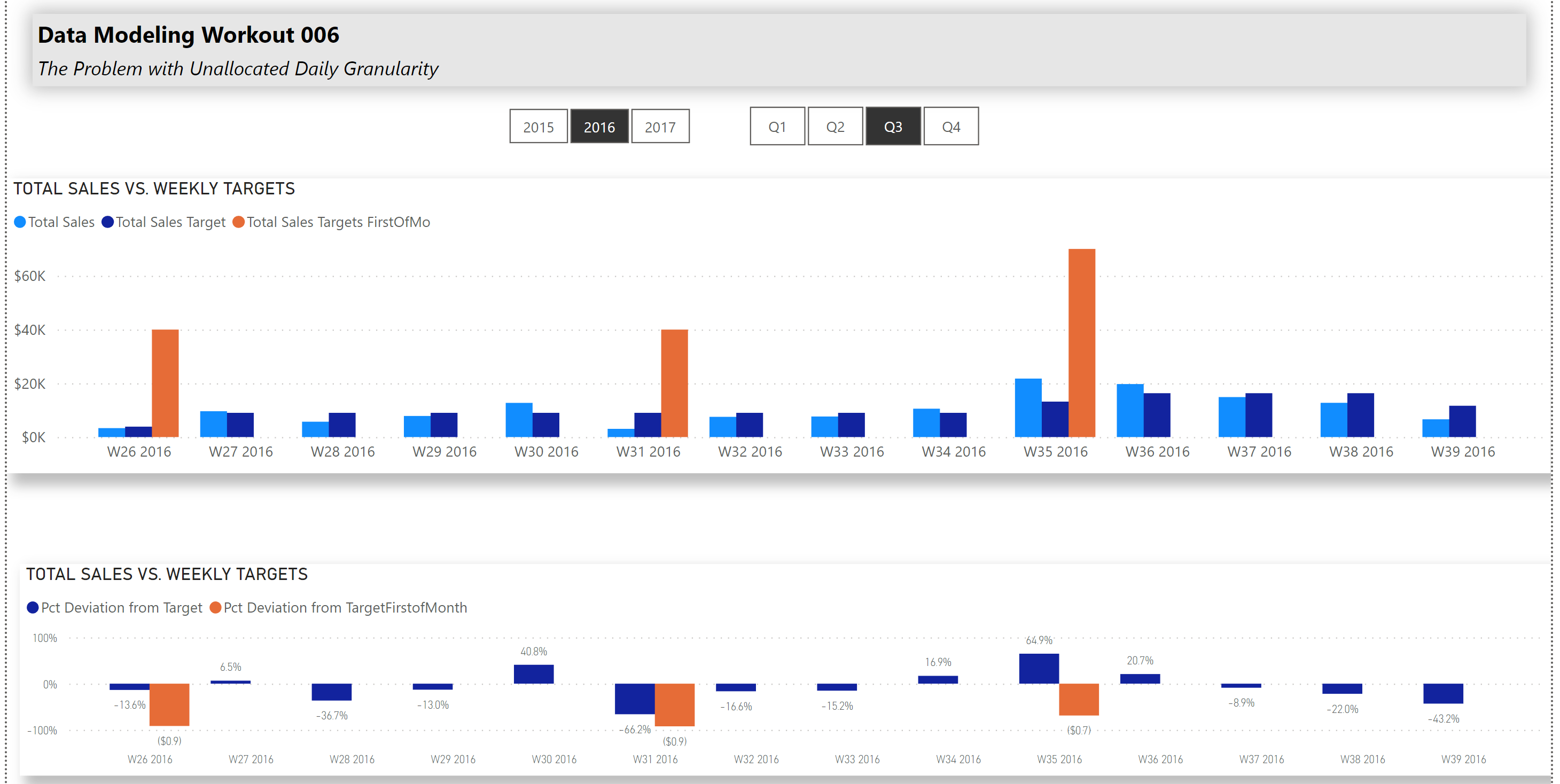
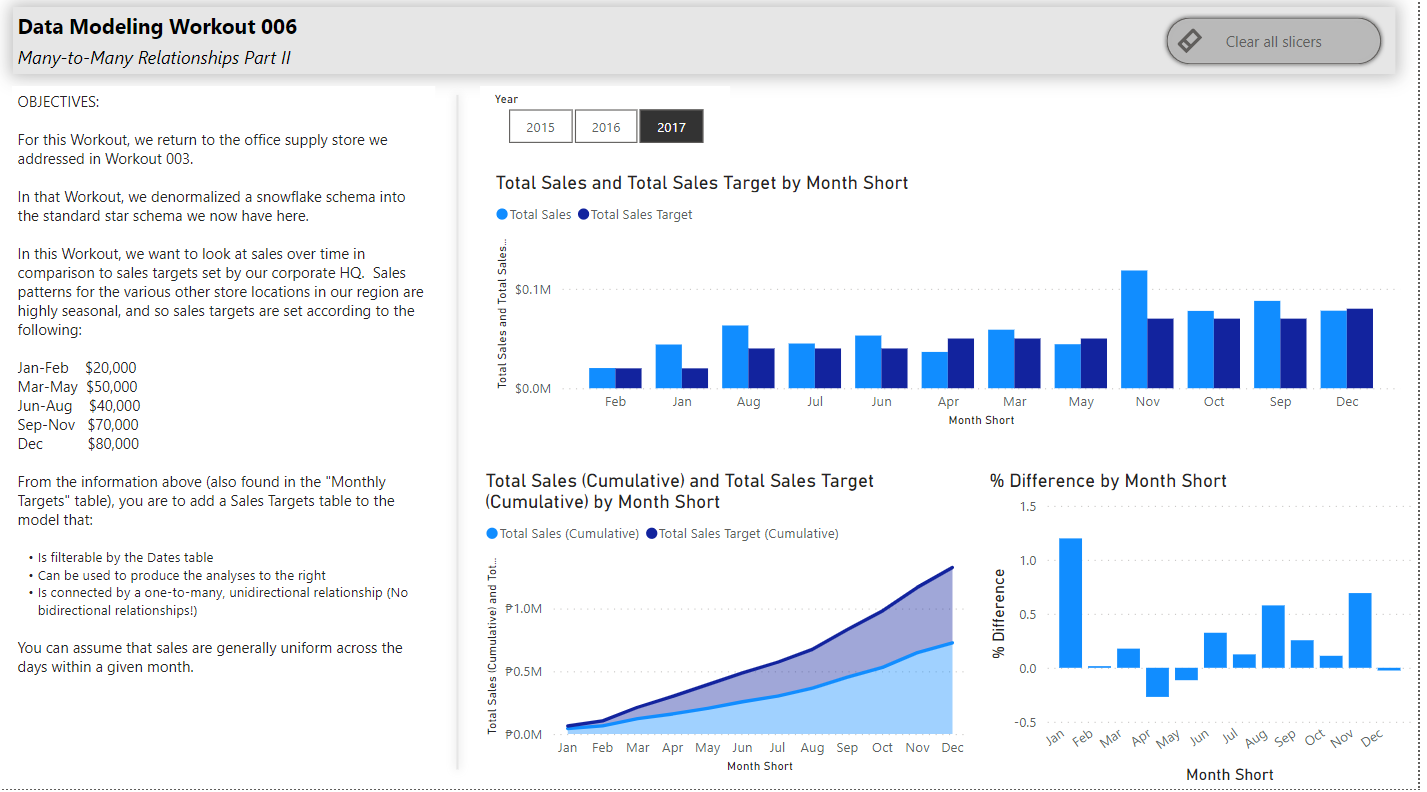
In this Workout, we want to look at sales over time in comparison to sales targets set by our corporate HQ. Sales patterns for the various other store locations in our region are highly seasonal, and so sales targets are set according to the following:
Jan-Feb $20,000
Mar-May $50,000
Jun-Aug $40,000
Sep-Nov $70,000
Dec $80,000
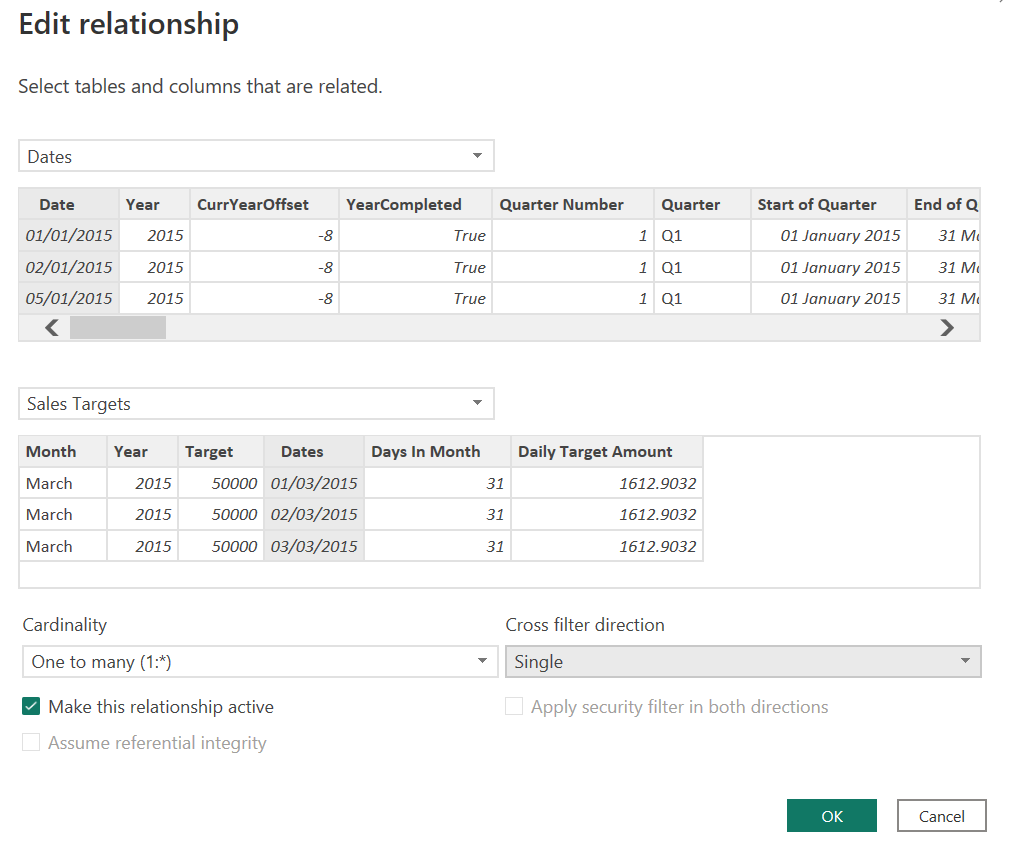
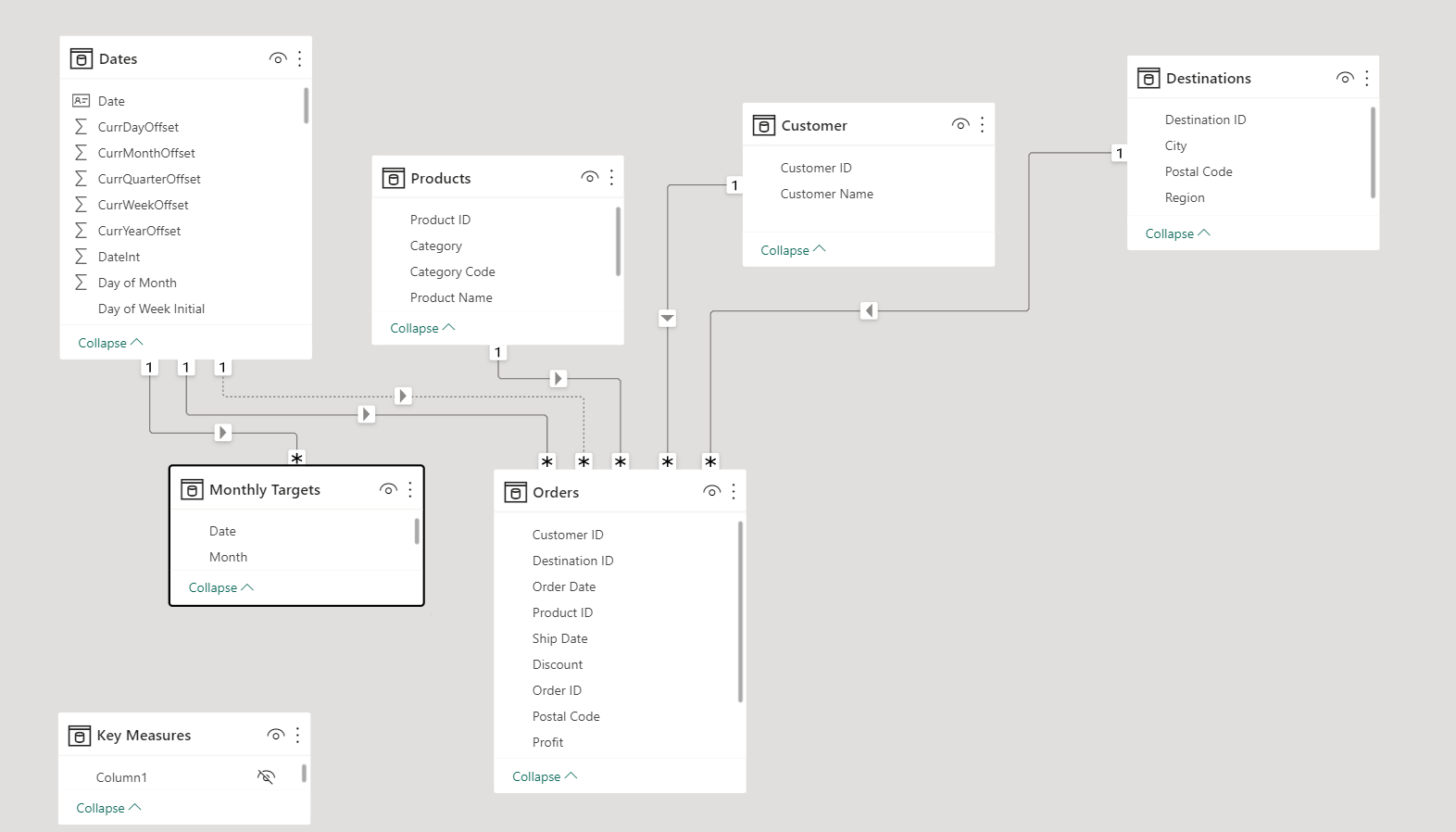
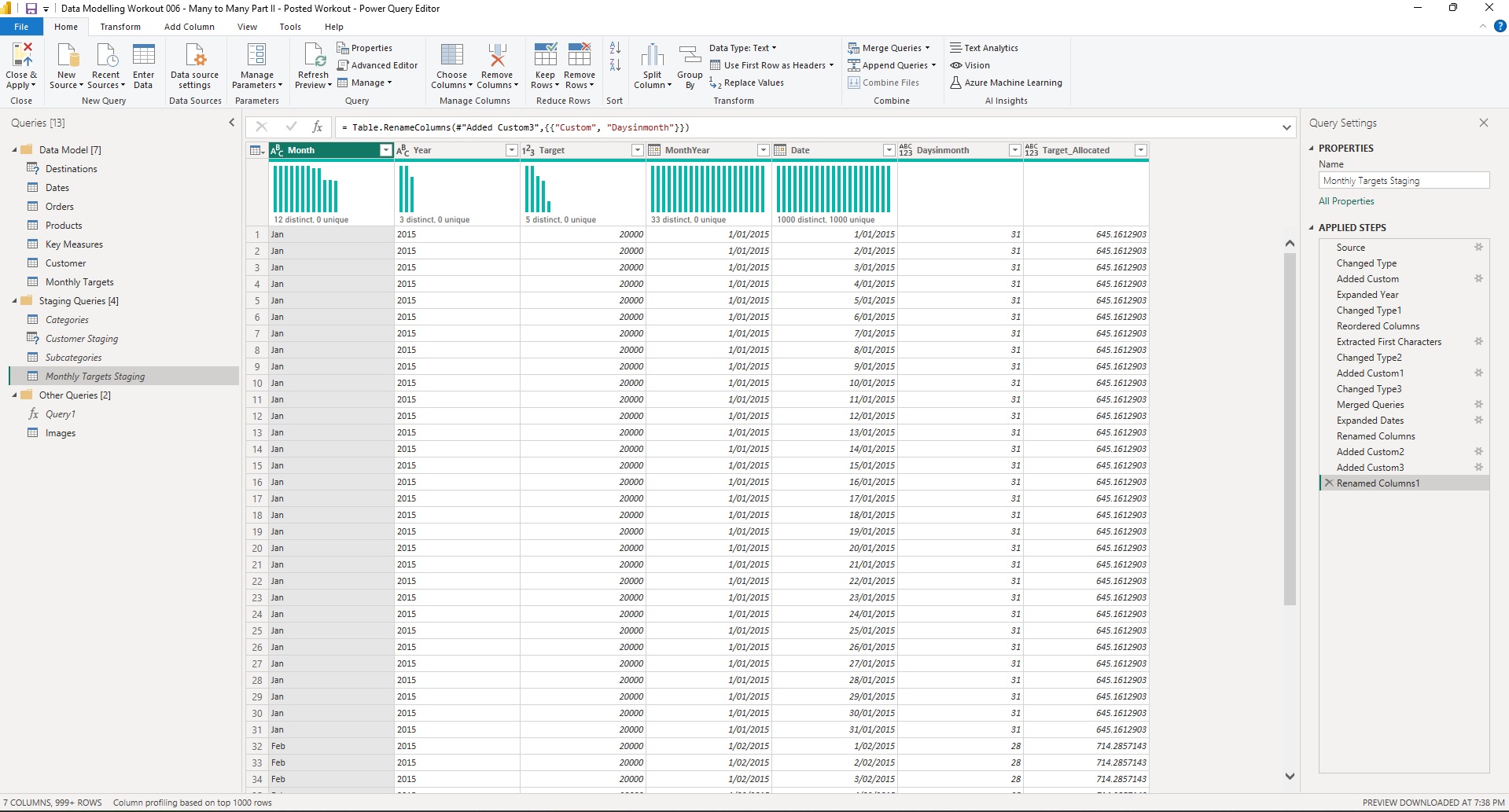
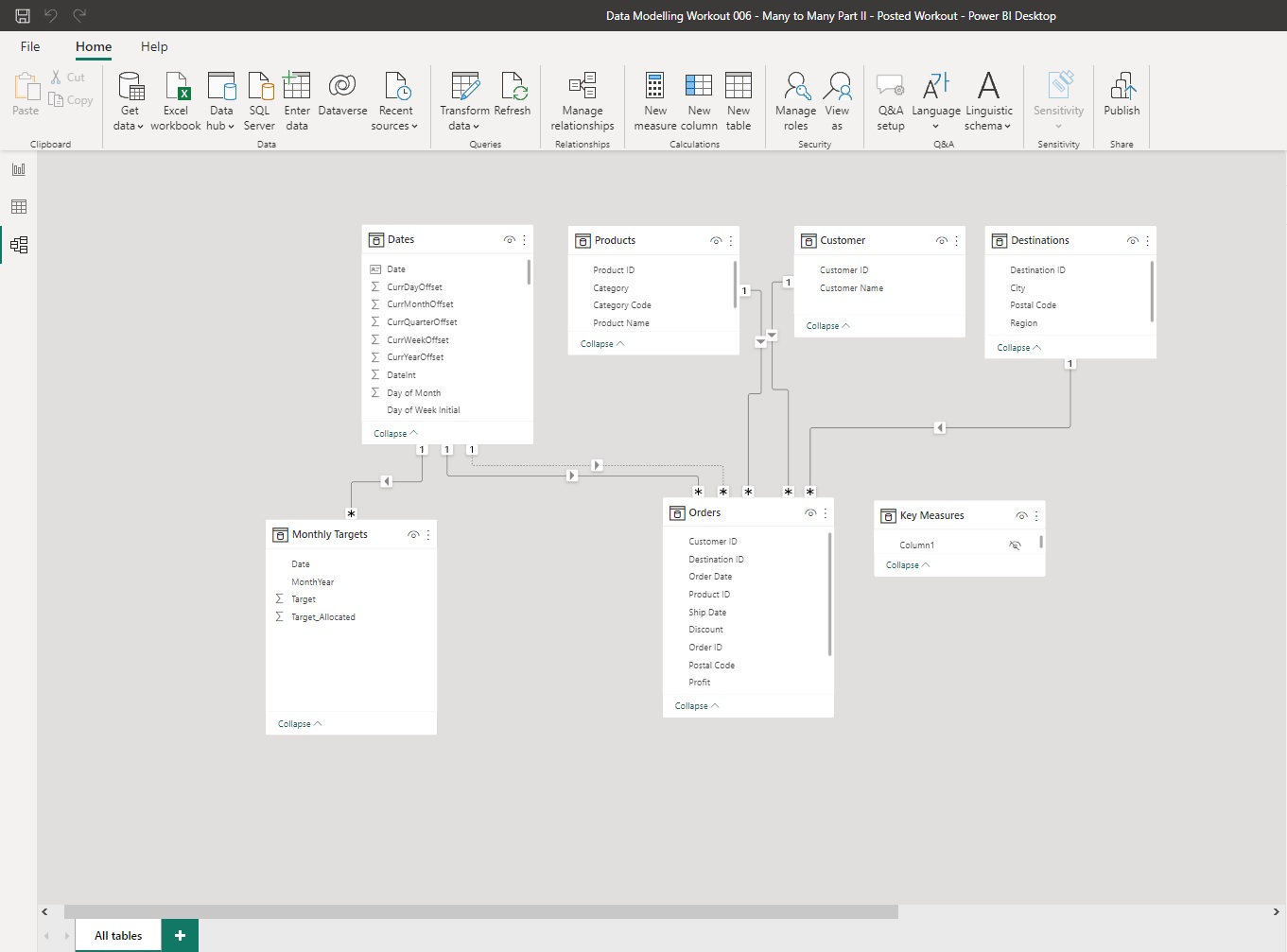
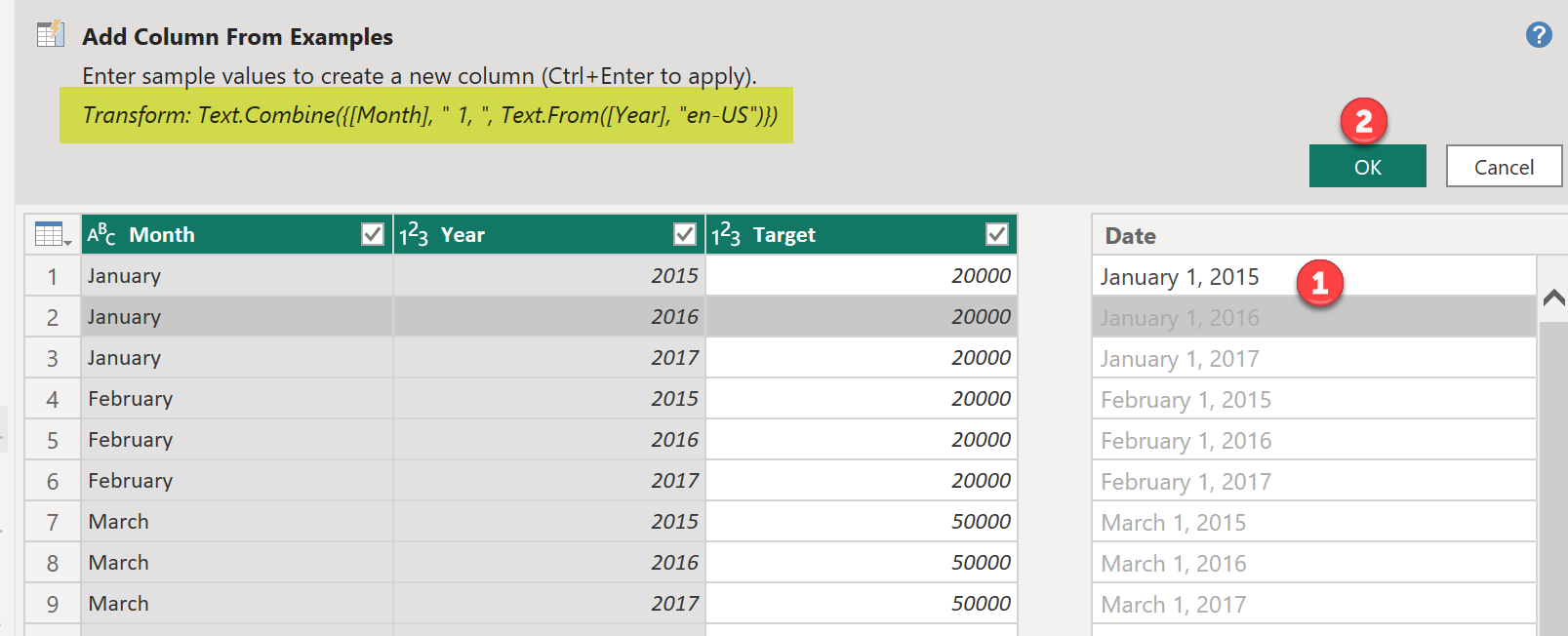
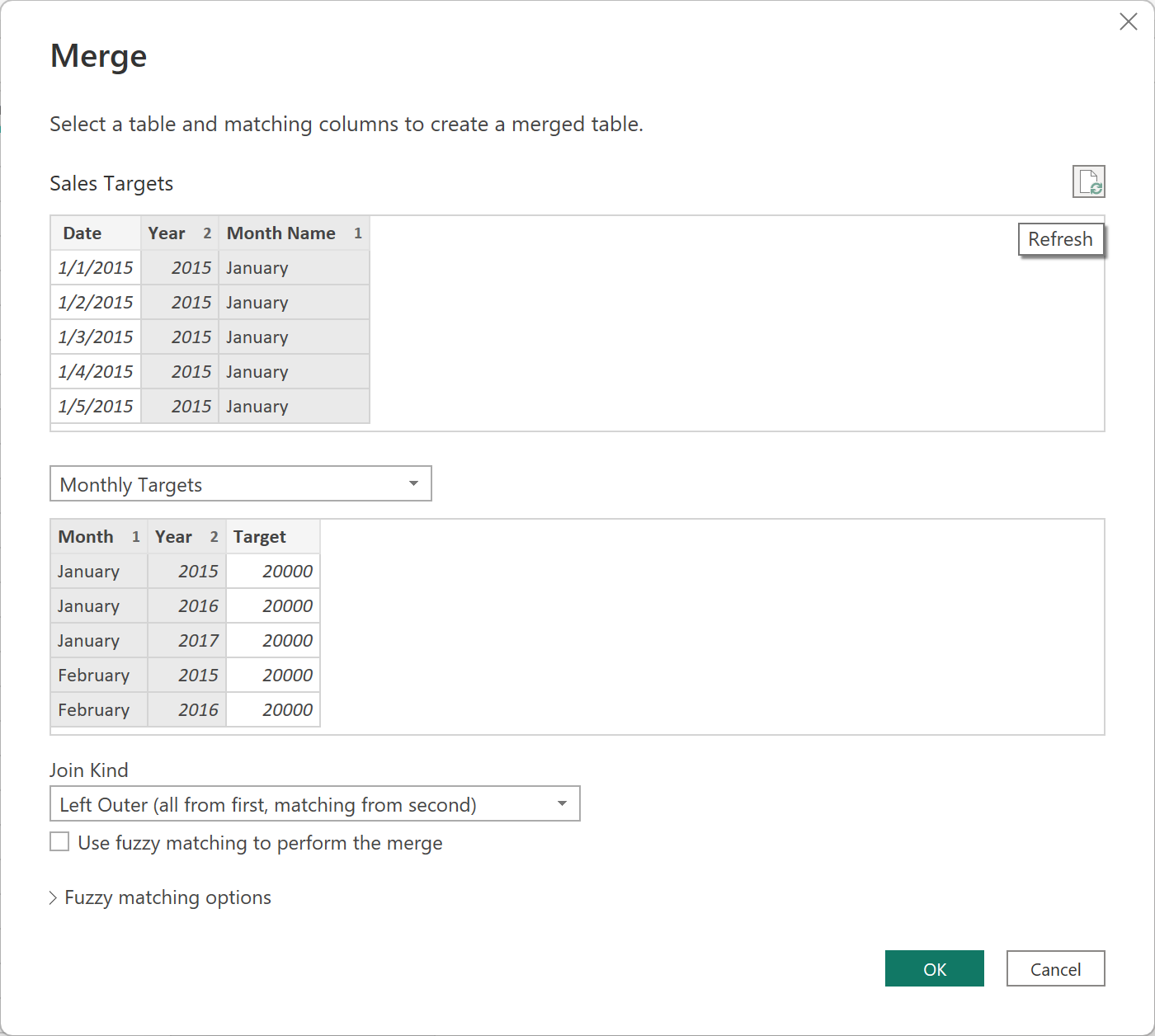
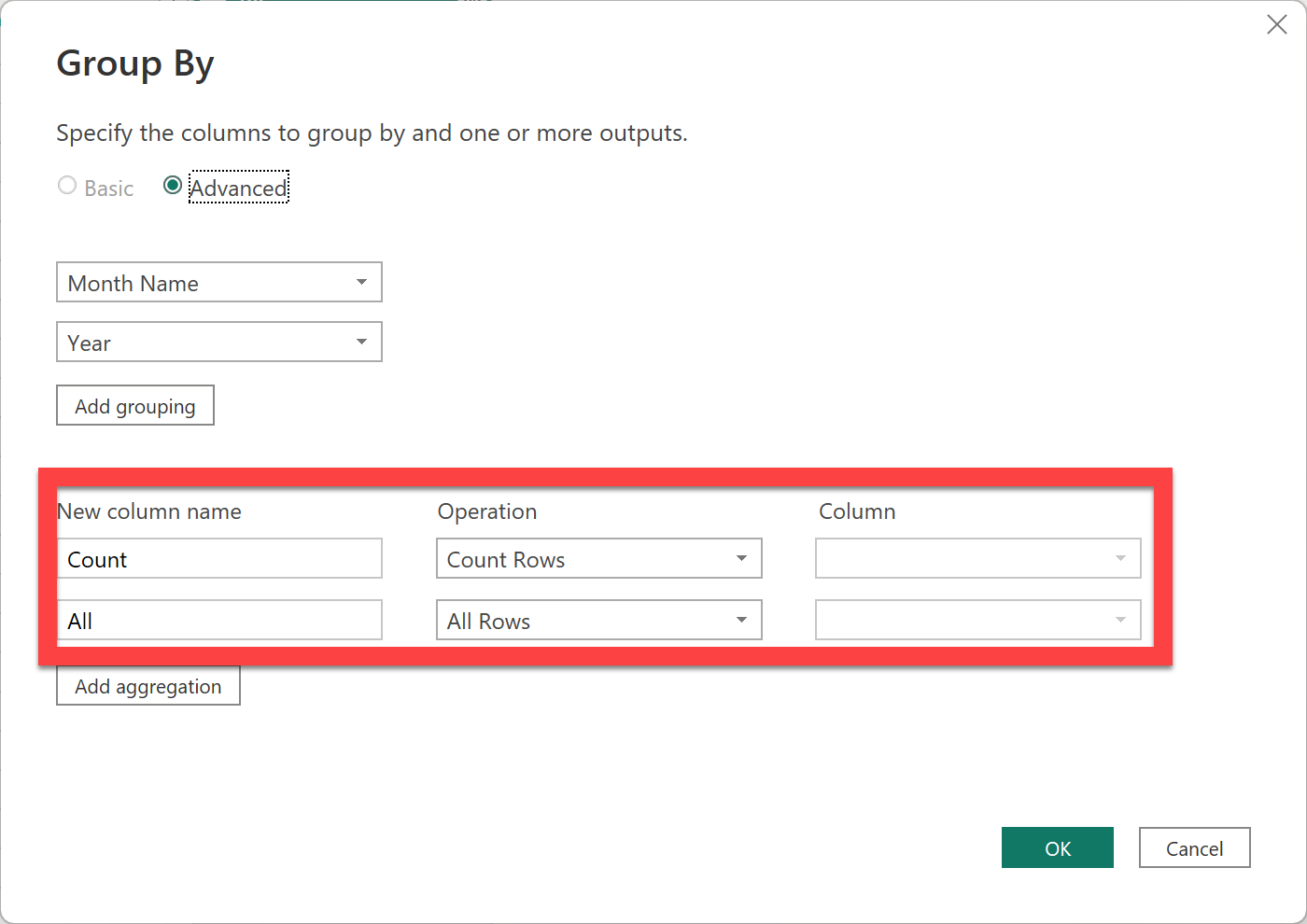
From the information above (also found in the “Monthly Targets” table in the PBIX attached), you are to add a Sales Targets table to the model that:
![]() Is filterable by the Dates table
Is filterable by the Dates table
![]() Can be used to produce the analyses below
Can be used to produce the analyses below
![]() Is connected by a one-to-many, unidirectional relationship (No bidirectional relationships!)
Is connected by a one-to-many, unidirectional relationship (No bidirectional relationships!)
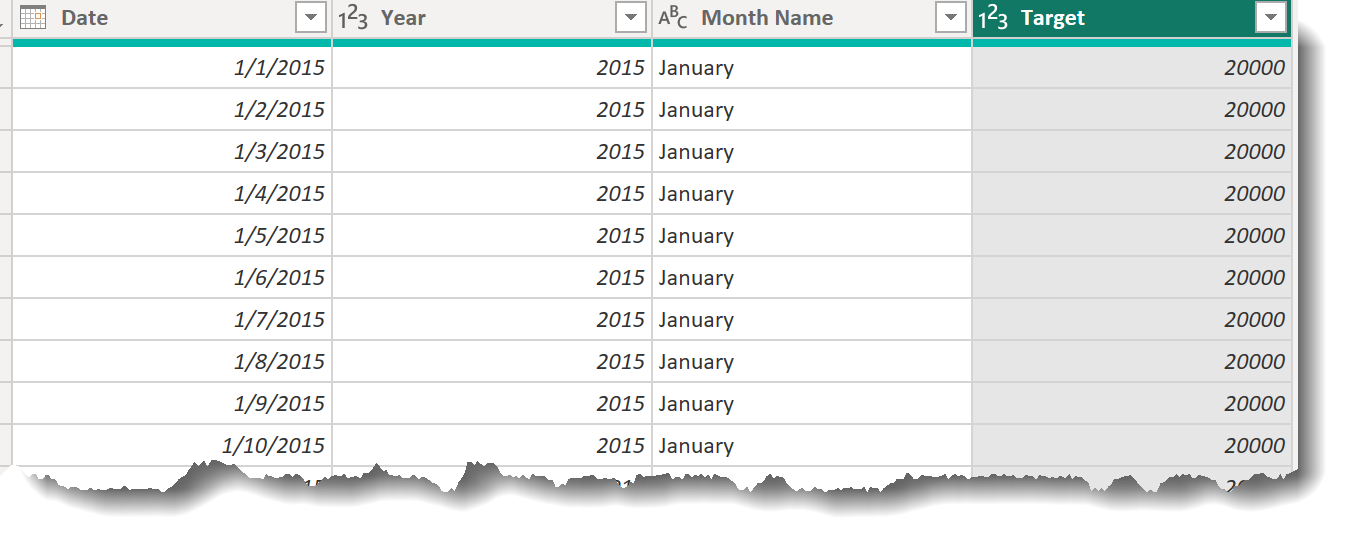
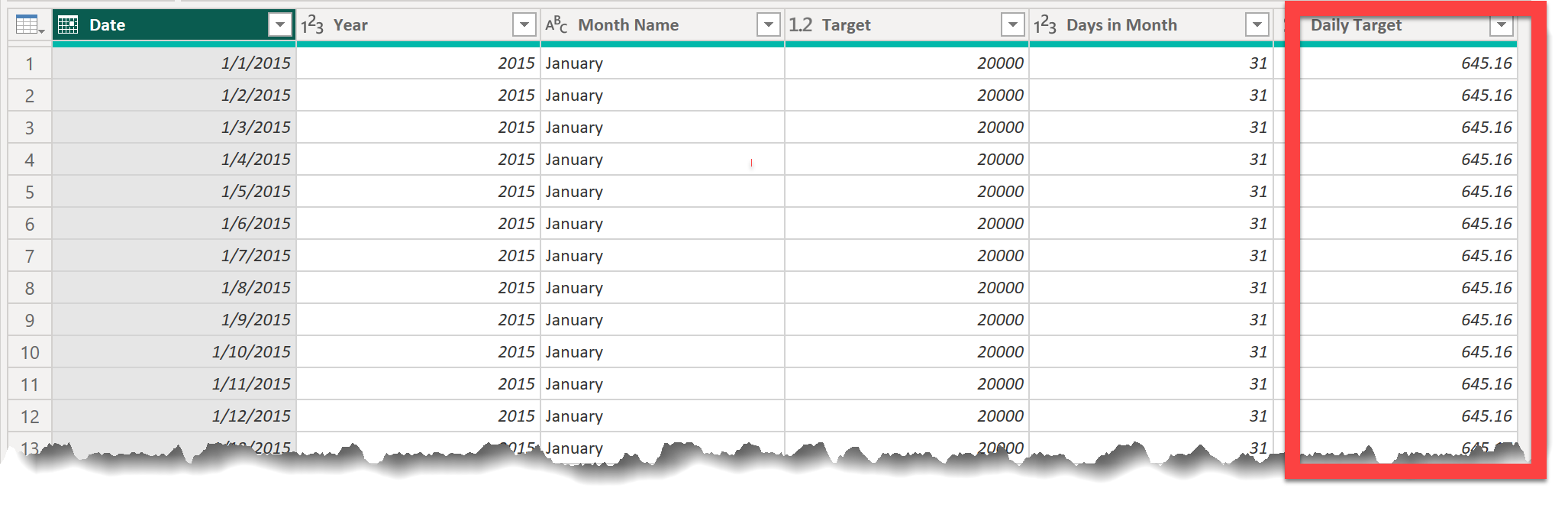
You can assume that sales are generally uniform across the days within a given month.
You can create the Sales Targets table however you’d like. I recommend Power Query, and I have confirmed that the Workout can be solved with no custom M code - only the UI (though feel free to use custom M if you’d like).
Here’s what the outcome should like when you’re done:
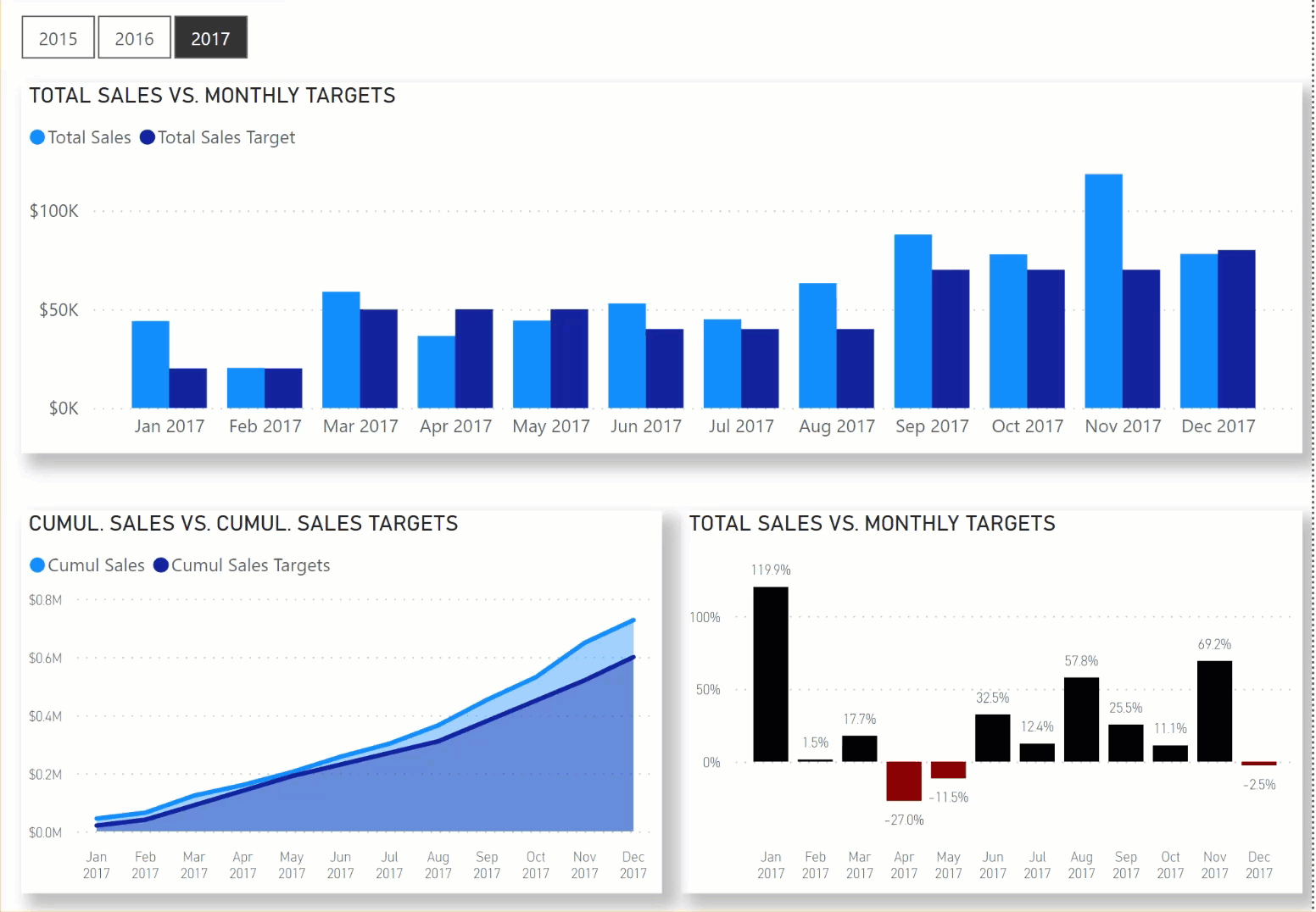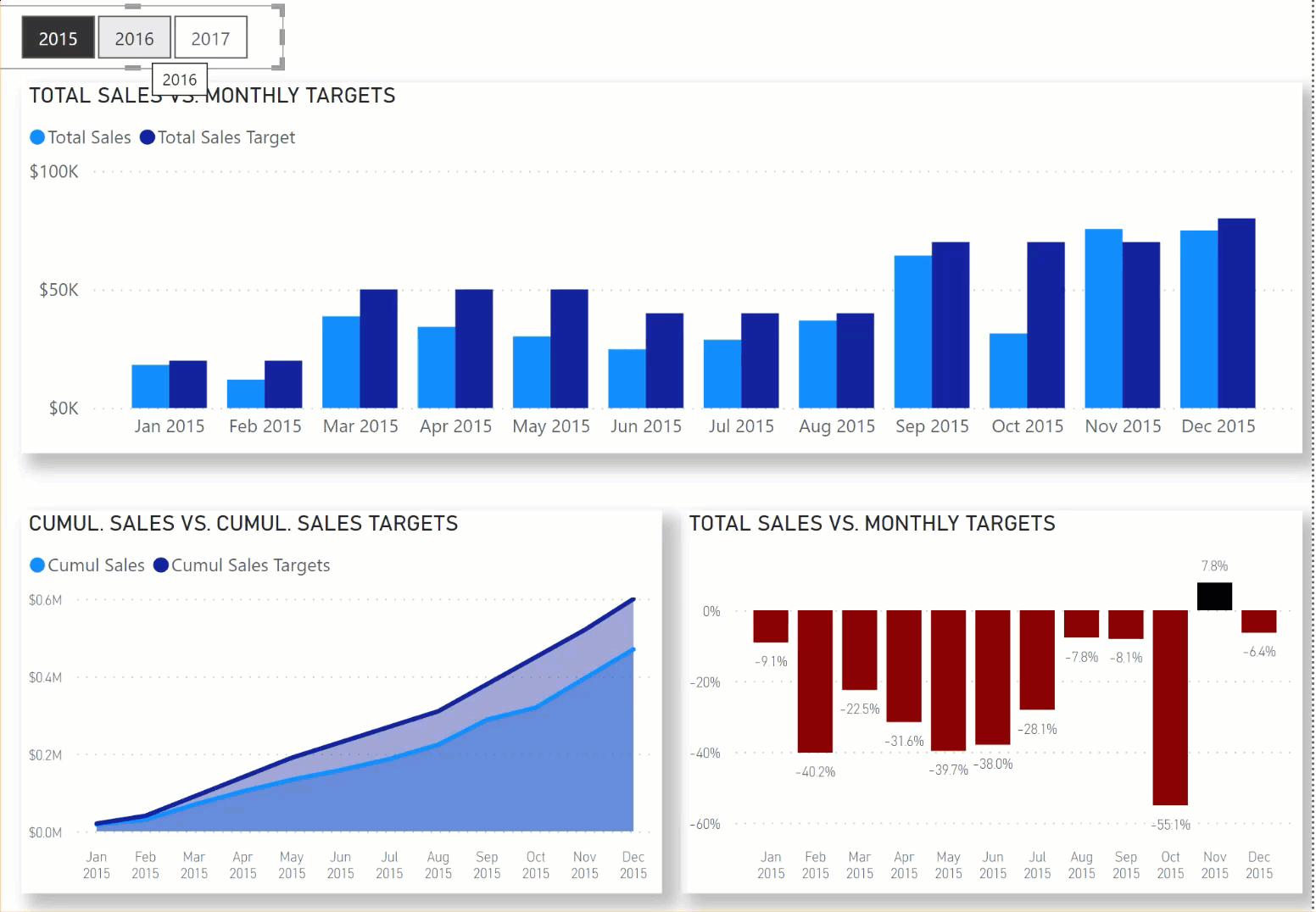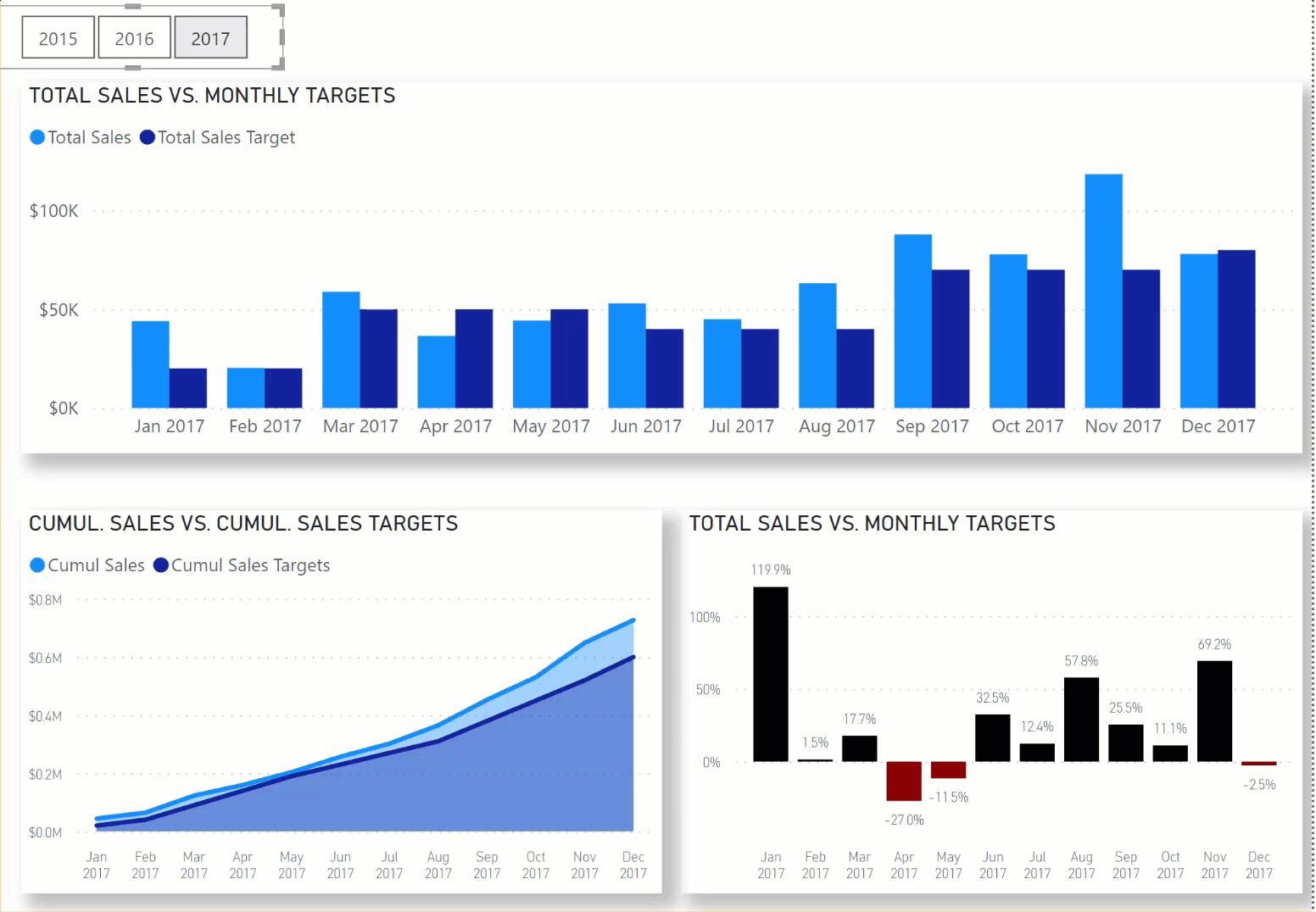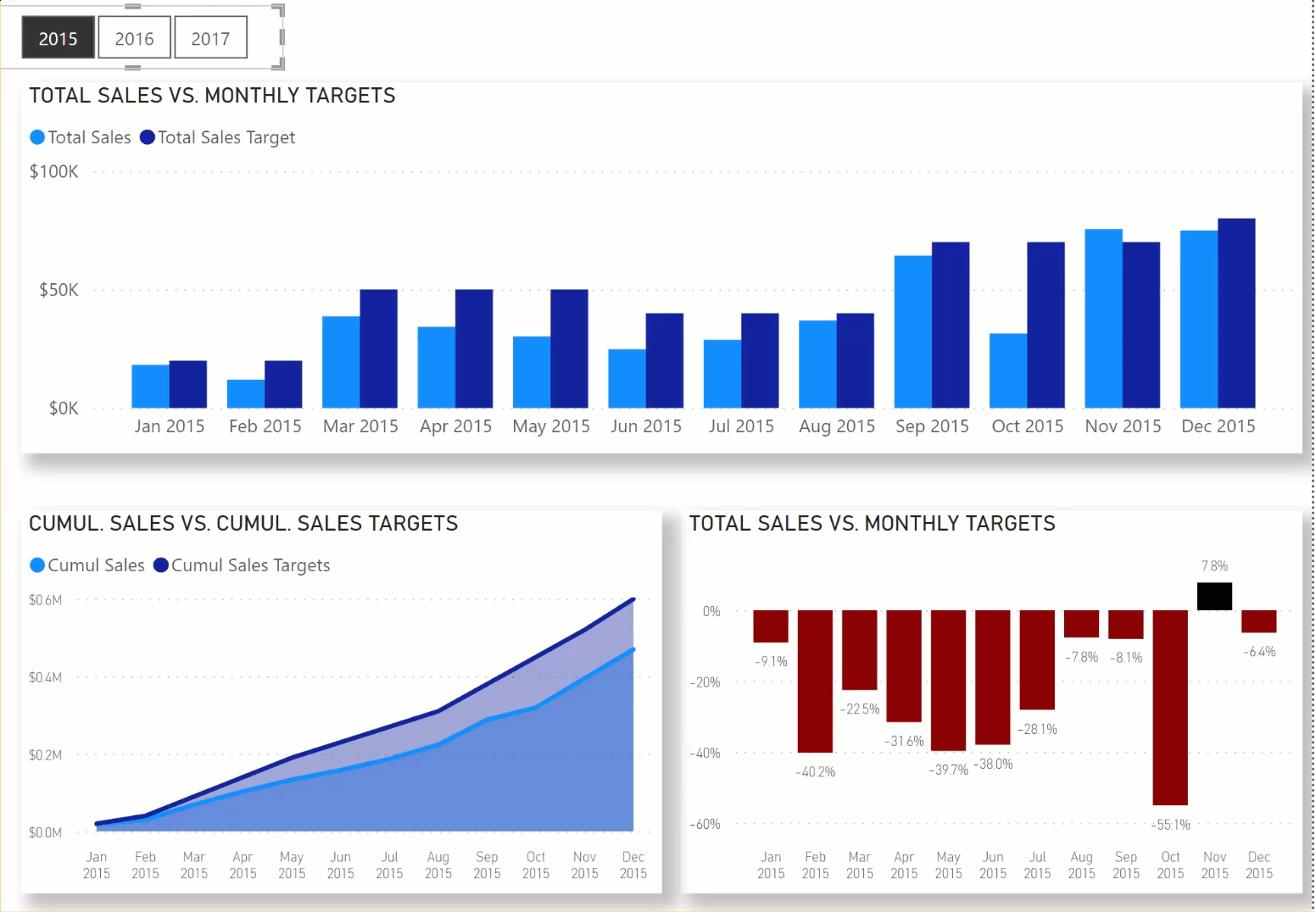
When you are done, please post your PBIX file, and a screenshot of your results. No need to hide anything on this one, since neither of these items will be “spoilers” for those who haven’t finished the workout yet.
Good luck!
Data Modelling Workout 006 - Many to Many Part II - Posted Workout.pbix (1.1 MB)
Data Modeling 003.xlsx (1.4 MB)