Here’s the challenge I am grappling with.
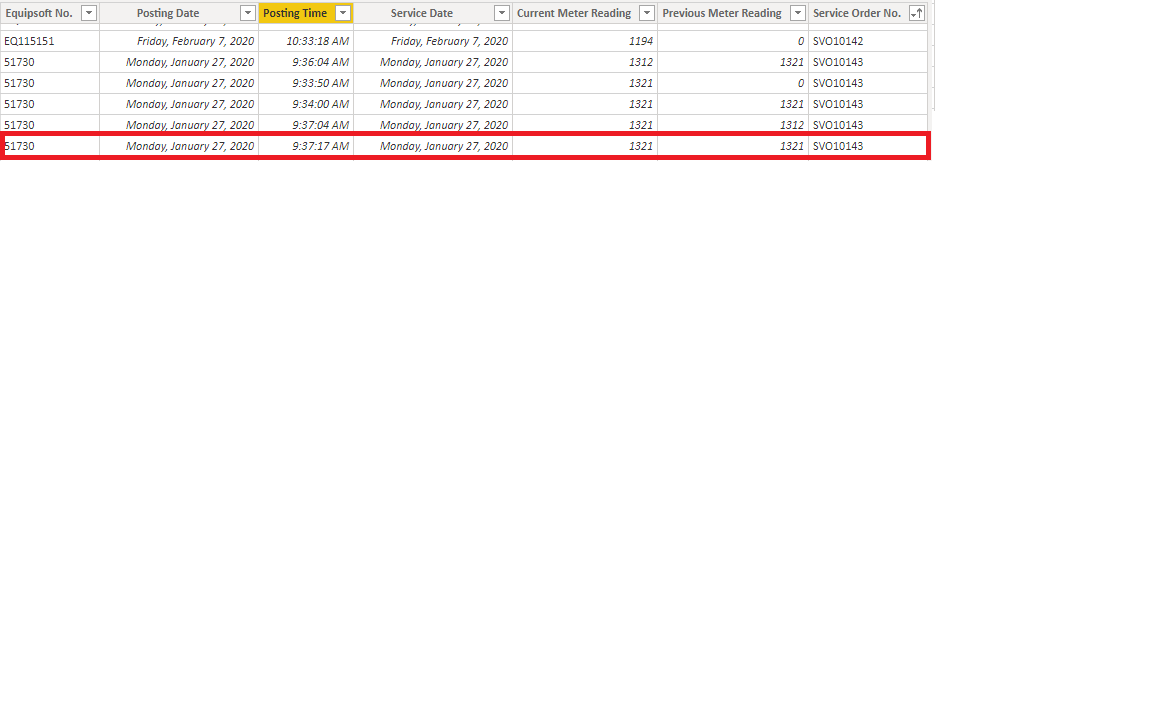
I have a fact table with hundreds of transactions related to Service Invoices. I need to pull in a dataset that contains what is called hour meters. Both the fact table and hour meter dataset have the common key of Service Orders No. But the hour meters dataset has rows with duplicate Service Order numbers due to corrections being made with the entry of the hour meter number. PowerBi immediately lets me know that there are duplicates and there would end up being a many to many relationship which I don’t want. My goal is to clean up the hour meter dataset. I can’t just arbitrarily delete duplicate Service Order numbers because I could actually incorrectly delete the corrected hour meter entry. The pattern that does exist is the date and time column does show the last time the entry was updated which is the one I want. Example data below.
My question is, what is the best approach to keeping the last update and deleting the unneeded rows. Is that even the right approach to do it in power query. Some of the duplicates can be as many as 4 or more. I am able to create a calculated column in PowerBi that uses RankX and I can filter, but it doesn’t help when it comes to the data model, which leads me to believe that I have to clean up the data in power query.